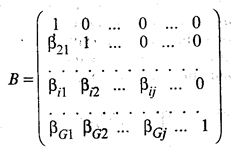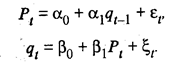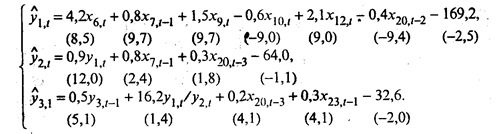| Главная » Учебно-методические материалы » СТАТИСТИКА » Курс социально-экономической статистики. Под ред. Назарова М.Г. |
| 23.01.2012, 00:02 | |
53.4. Кластерный анализВ статистических исследованиях группировка первичных данных является основным приемом решения задачи классификации, а поэтому и основой всей дальнейшей работы с собранной информацией. Традиционно эта задача решается следующим образом. Из множества признаков, описывающих объект, отбирается один, наиболее информативный, с точки зрения исследователя, и производится группировка данных в соответствии со значениями этого признака. Если требуется провести классификацию по нескольким признакам, ранжированным между собой по степени важности, то сначала осуществляется классификация по первому признаку, затем каждый из полученных классов разбивается на подклассы по второму признаку и т.д. Подобным образом строится большинство комбинационных статистических группировок. В тех случаях, когда не представляется возможным упорядочить классификационные признаки, применяется наиболее простой метод многомерной группировки — создание интегрального показателя (индекса), функционально зависящего от исходных признаков, с последующей классификацией по этому показателю. Развитием этого подхода является вариант классификации по нескольким обобщающим показателям (главным компонентам), полученным с помощью методов факторного или компонентного анализа. При наличии нескольких признаков (исходных или обобщенных) задача классификации может быть решена методами кластерного анализа, которые отличаются от других методов многомерной классификации отсутствием обучающих выборок, т.е. априорной информации о распределении генеральной совокупности. Различия между схемами решения задачи по классификации во многом определяются тем, что понимают под понятиями «сходство» и «степень сходства». После того как сформулирована цель работы, естественно попытаться определить критерии качества, целевую функцию, значения которой позволят сопоставить различные схемы классификации. В экономических исследованиях целевая функция, как правило, должна минимизировать некоторый параметр, определенный на множестве объектов (например, целью классификации оборудования может явиться группировка, минимизирующая совокупность затрат времени и средств на ремонтные работы). В случаях когда формализовать цель задачи не удается, критерием качества классификации может служить возможность содержательной интерпретации найденных групп. Рассмотрим следующую задачу. Пусть исследуется совокупность п объектов, каждый из которых характеризуется k измеренными признаками. Требуется разбить эту совокупность на однородные в некотором смысле группы (классы). При этом практически отсутствует априорная информация о характере распределения k-мерного вектора Х внутри классов. Полученные в результате разбиения группы обычно называются кластерами* (таксонами**, образами), методы их нахождения — кластер-анализом (соответственно численной таксономией или распознаванием образов с самообучением). * Clаster (англ.) — группа элементов, характеризуемых каким-либо общим свойством. **Тахоп (англ.) — систематизированная группа любой категории. Необходимо с самого начала четко представлять, какая из двух задач классификации подлежит решению. Если решается обычная задача типизации, то совокупность наблюдений разбивают на сравнительно небольшое число областей группирования (например, интервальный вариационный ряд в случае одномерных наблюдений) так, чтобы элементы одной такой области находились друг от друга по возможности на небольшом расстоянии. Решение другой задачи заключается в определении естественного расслоения результатов наблюдений на четко выраженные кластеры, лежащие друг от друга на некотором расстоянии. Если первая задача типизации всегда имеет решение, то во втором случае может оказаться, что множество наблюдений не обнаруживает естественного расслоения на кластеры, т.е. образует один кластер. Хотя многие методы кластерного анализа довольно элементарны, основная часть работ, в которых они были предложены, относится к последнему десятилетию. Это объясняется тем, что эффективное решение задач поиска кластеров, требующее выполнения большого числа арифметических и логических операций, стало возможным только с возникновением и развитием вычислительной техники. Обычной формой представления исходных данных в задачах кластерного анализа служит матрица
каждая строка которой представляет результаты измерений k рассматриваемых признаков у одного из обследованных объектов. В конкретных ситуациях может представлять интерес как группировка объектов, так и группировка признаков. В тех случаях, когда разница между двумя этими задачами не существенна, например при описании некоторых алгоритмов, мы будем пользоваться только термином «объект», включая в это понятие и термин «признак». Матрица Х не является единственным способом представления данных в задачах кластерного анализа. Иногда исходная информация задана в виде квадратной матрицы
элемент rij которой определяет степень близости i-го объекта к j-му. Большинство алгоритмов кластерного анализа полностью исходит из матрицы расстояний (или близостей) либо требует вычисления отдельных ее элементов, поэтому если данные представлены в форме X, то первым этапом решения задачи поиска кластеров будет выбор способа вычисления расстояний, или близости, между объектами или признаками. Несколько проще решается вопрос об определении близости между признаками. Как правило, кластерный анализ признаков преследует те же цели, что и факторный анализ: выделение групп связанных между собой признаков, отражающих определенную сторону изучаемых объектов. Мерой близости в этом случае служат различные статистические коэффициенты связи. Расстояние между объектами (кластерами) и мера близости Наиболее трудным и наименее формализованным в задаче классификации является определение понятия однородности объектов. В общем случае понятие однородности объектов задается введением либо правила вычисления расстояний ρ(xi, хj) между любой парой исследуемых объектов (x1, x2, ...,xn), либо некоторой функцией r(хi, xj), характеризующей степень близости i-го и j-го объектов. Если задана функция ρ(xi, хj), то близкие с точки зрения этой метрики объекты считаются однородными, принадлежащими к одному классу. Очевидно, что необходимо при этом сопоставлять ρ(xi, хj) с некоторыми пороговыми значениями, определяемыми в каждом конкретном случае по-своему. Аналогично используется и мера близости r(xi, хj), при задании которой мы должны помнить о необходимости выполнения следующих условий: симметрии r(xi, хj) = r(xj, хi); максимального сходства объекта с самим собой r(xi, хi) = Выбор метрики, или меры близости, является узловым моментом исследования, от которого в значительной степени зависит окончательный вариант разбиения объектов на классы при данном алгоритме разбиения. В каждом конкретном случае этот выбор должен производиться по-своему, в зависимости от целей исследования, физической и статистической природы наблюдений, априорных сведений о характере вероятностного распределения X. Рассмотрим наиболее широко используемые в задачах кластерного анализа расстояния и меры близости. Обычное евклидово расстояние определяется по формуле
где xil, хjl — значения l-го признака у i-го (j-го) объекта (l = 1, 2, ..., k, i,j = 1, 2, .... п). Оно используется в следующих случаях: а) наблюдения берутся из генеральной совокупности, имеющей многомерное нормальное распределение с ковариационной матрицей вида σ2Ek, где Еk — единичная матрица, т.е. исходные признаки взаимно независимы и имеют одну и ту же дисперсию; б) исходные признаки однородны по физическому смыслу и одинаково важны для классификации. Естественное с геометрической точки зрения евклидово пространство может оказаться бессмысленным (с точки зрения содержательной интерпретации), если признаки измерены в разных единицах. Чтобы исправить положение, прибегают к нормированию каждого признака путем деления центрированной величины на среднее квадратическое отклонение и переходят от матрицы Х к нормированной матрице с элементами
где xil — значение l-го признака у i-го объекта;
Однако эта операция может привести к нежелательным последствиям. Если кластеры хорошо разделимы по одному признаку и не разделимы по другому, то после нормирования дискриминирующие возможности первого признака будут уменьшены в связи с усилением «шумового» эффекта второго. «Взвешенное» евклидово расстояние определяется из выражения
Оно применяется в тех случаях, когда каждой l-й компоненте вектора наблюдений Х удается приписать некоторый «вес» ω1, пропорциональный степени важности признака в задаче классификации. Обычно принимают 0 ≤ ωl ≤ 1, где l = 1,2, ..., k. Определение весов, как правило, связано с дополнительными исследованиями, например с организацией опроса экспертов и обработкой их мнений. Определение весов ωl только по данным выборки может привести к ложным выводам. Хеммингово расстояние используется как мера различия объектов, задаваемых дихотомическими признаками. Это расстояние определяется по формуле
и равно числу несовпадений значений соответствующих признаков в рассматриваемых i-м и j-м объектах. Как правило, решение задач классификации многомерных данных предусматривает в качестве предварительного этапа исследования реализацию методов, позволяющих выбрать из k исходных признаков x1, x2, ..., xk сравнительно небольшое число наиболее информативных, т.е. уменьшить размерность наблюдаемого пространства. В ряде процедур классификации (кластер-процедур) используют понятия расстояния между группами объектов и меры близости двух групп объектов. Пусть Si — i-я группа (класс, кластер), состоящая из ni объектов;
ρ(Sl, Sm) — расстояние между группами Sl и Sm. Наиболее употребительными расстояниями и мерами близости между классами объектов являются: • расстояние, измеряемое по принципу «ближайшего соседа»:
• расстояние, измеряемое по принципу «дальнего соседа»:
• расстояние, измеряемое по «центрам тяжести» групп:
где xl и xm — векторы средних соответственно Sl и Sm кластеров; • расстояние, измеряемое по принципу «средней связи», определяемое как среднее арифметическое всех попарных расстояний между представителями рассматриваемых групп:
Академиком А.Н. Колмогоровым было предложено «обобщенное расстояние» между классами, которое включает в себя в качестве частных случаев все рассмотренные выше виды расстояний. Расстояния между группами элементов — особенно важный параметр в так называемых агломеративных иерархических кластер-процедурах, так как принцип работы таких алгоритмов состоит в последовательном объединении элементов, а затем и целых групп: сначала — самых близких, а впоследствии — все более и более отдаленных друг от друга. При этом расстояние между кластером Sl и кластером S(m,q), являющимся объединением двух других кластеров — Sm и Sq можно определить по формуле
где ρlm = ρ (Sl, Sm); ρlq = ρ (Sl, Sq) и ρmq = ρ (Sm, Sq) - расстояния между кластерами Sl, Sm и Sq; α, β, γ и δ — числовые коэффициенты, значения которых определяют специфику процедуры, ее алгоритм. Например, при α = β = -δ = 1/2 и γ = 0 приходим к расстоянию, построенному по принципу «ближайшего соседа». При α = β = δ = 1/2 и γ = 0 расстояние между классами определяется по принципу «дальнего соседа», т.е. как расстояние между двумя самыми дальними элементами этих классов. Функционалы качества разбиения Существует большое количество различных способов разбиения заданной совокупности элементов на классы. Поэтому представляет интерес задача сравнительного анализа качества этих способов разбиения Q(S), определенного на множестве всех возможных разбиений. Тогда под наилучшим разбиением S* понимаем такое разбиение, при котором достигается экстремум выбранного функционала качества. Следует отметить, что выбор того или иного функционала качества, как правило, опирается на эмпирические соображения. Рассмотрим наиболее распространенный функционал качества разбиения. Пусть исследователем выбрана метрика ρ в пространстве Х и пусть S = (S1, S2,..., Sp) — некоторое фиксированное разбиение наблюдений x1, ..., xn на заданное число p классов S1, S2, ..., Sp. За функционал качества берут сумму («взвешенную») внутриклассовых дисперсий
где xl — вектор средних для l-го кластера. Иерархические кластер-процедуры Иерархические (древообразные) процедуры являются наиболее распространенными (в смысле реализации на ЭВМ) алгоритмами кластерного анализа. Они бывают двух типов: агломеративные и дивизимные. В агломеративных процедурах начальным является разбиение, состоящее из п одноэлементных классов, а конечным — состоящее из одного класса; в дивизимных — наоборот. Принцип работы иерархических агломеративных (дивизимных) процедур состоит в последовательном объединении (разделении) групп элементов, сначала самых близких (далеких), а затем — все более отдаленных (близких) друг от друга. Большинство этих алгоритмов исходит из матрицы расстояний. К недостаткам иерархических процедур следует отнести громоздкость их численной реализации. Алгоритмы требуют вычисления матрицы расстояний на каждом шаге, а следовательно, емкой машинной памяти и большого количества времени. В этой связи реализация таких алгоритмов при числе наблюдений, большем нескольких сотен, нецелесообразна, а в ряде случаев и невозможна. В качестве примера рассмотрим агломеративный иерархический алгоритм. На первом шаге алгоритма каждое наблюдение xi (i = 1, 2, ..., п) рассматривается как отдельный кластер. В дальнейшем на каждом шаге работы алгоритма происходит объединение двух самых близких кластеров, и с учетом принятого расстояния по формуле пересчитывается матрица расстояний, размерность которой, очевидно, снижается на единицу. Работа алгоритма заканчивается, когда все наблюдения объединены в один класс. Большинство программ, реализующих алгоритм иерархической классификации, предусматривает графическое представление результатов классификации в виде дендрограммы. Пример. Классификация стран по уровню жизни населения В табл. 53.4 представлены значения следующих шести показателей, характеризующих условия жизни населения двадцати стран в 1994 г.: x1 — потребление мяса и мясопродуктов на душу населения (кг); х2 — смертность населения по причине болезни органов кровообращения на 100 тыс. человек; х3 — оценка валового внутреннего продукта по паритету покупательной способности в 1994 г. на душу населения (в % по отношению к США); x4 — расходы на здравоохранение (в % от ВВП); x5 — потребление фруктов и ягод на душу населения (кг); x6 — потребление хлебопродуктов на душу населения (кг). Провести классификацию стран по уровню жизни населения и дать содержательную интерпретацию полученных результатов. Таблица 53.4 Макроэкономические показатели уровня жизни населения (1994 г.)
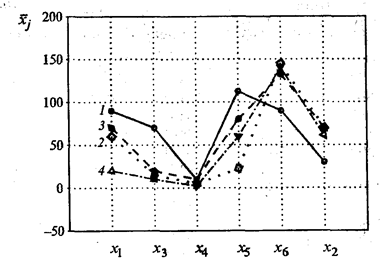
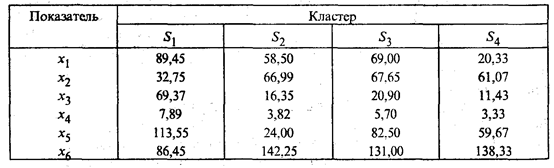
Решение. В условии задачи не оговорены число классов разбиения и вид законов распределения, а также не даны обучающие выборки. В этой связи при классификации использовались методы кластерного анализа. Исходная информация (табл. 53.4) показывает, что в рассматриваемую совокупность входят страны бывшего СССР, Восточной Европы и промышленно развитые страны. Поэтому можно предположить, что искомое разбиение стран по уровню жизни населения будет состоять из трех или четырех кластеров. Классификация проводилась по различным алгоритмам кластерного анализа, но наилучшими в содержательном плане оказались результаты, полученные при разбиении стран на четыре класса. В первый кластер вошли одиннадцать (n1 =11) стран: Австралия, Австрия, Бельгия, Великобритания, Германия, Греция, Дания, Ирландия, Испания, Италия, Канада. Наиболее удалена от центра этого кластера Италия, которая характеризуется самым высоким для кластера уровнем потребления фруктов (х5) и хлебопродуктов (x6). Во второй кластер вошли четыре (п2 = 4) страны: Россия, Белоруссия, Казахстан и Киргизия. В третий кластер вошли две (n3 = 2) страны: Болгария и Венгрия. В четвертый кластер вошли три (п4 = 3) страны: Азербайджан, Армения и Грузия. Средние значения показателей для четырех кластеров представлены на рис. 53.3 и в табл. 53.5.
Рис. 53.3. Средние значения показателей для каждого кластера (цифры у кривых соответствуют номерам кластеров) Таблица 53.5 Средние значения показателей
Кластер S1, в который входят промышленно развитые страны Запада, характеризуется (рис. 53.3) самыми высокими значениями: ВВП по паритету покупательной способности (x3), расходов на здравоохранение (х4), потребления мяса (x1) и фруктов (х5), а также самым низким значением смертности (х2). Самое высокое потребление хлебопродуктов на душу населения (х6) у стран, входящих в кластеры S2 и S4. В кластер S4 вошли страны, на территории которых происходили в рассматриваемый период вооруженные конфликты. Этот кластер характеризуется самыми низкими средними значениями показателей х3 и х4, а также x1 — среднедушевым потреблением мяса. Заслуживает внимания матрица расстояний между центрами четырех кластеров:
Из матрицы следует, что кластеры S2, S3 и S4 примерно одинаково удалены друг от друга. Евклидово расстояние между ними равно соответственно 60,7; 53,0 и 55,5. Наиболее выделяется по уровню жизни населения кластер S1. Расстояния между S1 и кластерами S2, S3 и S4 равны соответственно 126,8; 83,3 и 120,6. 53.5. Основы эконометрикиЭконометрика — это дисциплина, объединяющая совокупность теоретических результатов, методов и приемов, позволяющих на базе экономической теории, экономической статистики и математико-статистического инструментария получать количественное выражение качественных закономерностей. Курс эконометрики призван научить различным способам выражения связей и закономерностей через эконометрические модели и методы проверки их адекватности, основанные на данных наблюдений. От математико-статистического эконометрический подход отличается тем вниманием, которое уделяется в нем вопросу соответствия выбранной модели изучаемому объекту, рассмотрению причин, приводящих к необходимости пересмотра модели на основе более точной системы представлений. Эконометрика занимается, по существу, статистическими выводами, т.е. использованием выборочной информации для получения некоторого представления о свойствах генеральной совокупности. Наиболее распространенными эконометрическими моделями являются производственные функции и модели, описываемые системой одновременных уравнений. Кратко остановимся на них. Производственные функции Производственная функция представляет собой математическую модель, характеризующую зависимость объема выпускаемой продукции от объема трудовых и материальных затрат. Модель может быть построена как для отдельной фирмы и отрасли, так и для всей национальной экономики. Рассмотрим производственную функцию, включающую два фактора производства — затраты капитала К и трудовые затраты L, определяющие объем выпуска Q. Тогда можно записать
Определенного уровня выпуска можно достигнуть с помощью различного сочетания капитальных и трудовых затрат. Кривые, описываемые условиями j(K, L) = const., называются изо квантами. Обычно предполагается, что по мере роста значений одной из независимых переменных предельная норма замещения данного фактора производства уменьшается. Поэтому при сохранении постоянного объема производства экономия одного вида затрат, связанная с увеличением затрат другого фактора, постепенно уменьшается. На примере производственной функции Кобба — Дугласа рассмотрим основные выводы, которые можно получить исходя из предложений о том или ином виде производственной функции. Производственная функция Кобба — Дугласа, включающая два фактора производства, имеет вид
где А, α, β — параметры модели. Величина А зависит от единиц измерения Q, К и L, а также от эффективности производственного процесса. При фиксированных значениях К и L более высокое значение имеет та функция Q, которая характеризуется большей величиной параметра А, следовательно, и производственный процесс, описываемый такой функцией, более эффективен. Описываемая производственная функция однозначна и непрерывна (при положительных К и L). Параметры α и β называют коэффициентами эластичности. Они показывают, на какую величину в среднем изменится Q, если α или β увеличить на 1%. Рассмотрим поведение функции Q при изменении масштабов производства. Предположим, что затраты каждого фактора производства увеличились в с раз. Тогда новое значение функции будет определяться следующим образом:
При этом, если α + β = 1, то уровень эффективности не зависит от масштабов производства. Если α + β < 1, то средние издержки, рассчитанные на единицу продукции, растут, а при α + β > 1 — убывают по мере расширения масштабов производства. Следует отметить, что эти свойства не зависят от численных значений К, L производственной функции. Для определения параметров и вида производственной функции необходимо провести дополнительные наблюдения. Как правило, пользуются двумя видами данных — динамическими (временными) рядами и данными одновременных наблюдений (пространственной информацией). Динамические ряды экономических показателей характеризуют поведение одной и той же фирмы во времени, тогда как данные второго вида обычно относятся к одному и тому же моменту, но к различным фирмам. В случаях когда исследователь располагает временным рядом, например годовыми данными, характеризующими деятельность одной и той же фирмы, возникают трудности, с которыми не пришлось бы столкнуться при работе с пространственными данными. Так, относительные цены со временем становятся иными, а следовательно, меняется и оптимальное сочетание затрат отдельных факторов производства. Кроме того, с течением времени изменяется и уровень административного управления. Однако основные проблемы при использовании временных рядов порождаются последствиями технического прогресса, в результате которого меняются нормы затрат производственных факторов, соотношения, в которых они могут замещать друг друга, и параметры эффективности. Вследствие этого с течением времени могут меняться не только параметры, но и формы производственной функции. Поправка на технический прогресс может быть введена с помощью некоторого временного тренда, включаемого в состав производственной функции. Тогда
Производственная функция Кобба — Дугласа с учетом технического прогресса имеет вид
В этом выражении параметр θ, с помощью которого характеризуется технический прогресс, показывает, что объем выпускаемой продукции ежегодно увеличивается на θ процентов независимо от изменений в затратах производственных факторов и, в частности, от размера новых инвестиций. Такая форма технического прогресса, не связанная с какими-либо затратами труда или капитала, называется «нематеризованным техническим прогрессом». Однако подобный подход не вполне реалистичен, так как новые открытия не могут повлиять на функционирование старых машин, а расширение объема производства возможно только посредством новых инвестиций. При другом подходе к учету технического прогресса для каждой «возрастной группы» капитала строят свою производственную функцию. В этом случае функция Кобба — Дугласа будет иметь вид
где Qt(v) — объем продукции, произведенной за период t на оборудовании, введенном в строй в период v; Lt(v) — трудовые затраты в период t на обслуживание оборудования, введенного в строй в период v, и Кt(v) — основной капитал, введенный в строй в период v и использованный в период t. Параметр v в такой производственной функции отражает состояние технического прогресса. Затем для периода t строится агрегированная производственная функция, представляющая собой зависимость совокупного объема выпускаемой продукции Qt от общих затрат труда Lt, и капитала Кt на момент t. При использовании для построения производственной функции пространственной информации, т.е. данных о нескольких фирмах, соответствующих одному и тому же моменту времени, возникают проблемы другого рода. Так как результаты наблюдений относятся к разным фирмам, то при их использовании предполагается, что поведение всех фирм может быть описано с помощью одной и той же функции. Для успешной экономической интерпретации полученной модели желательно, чтобы все эти фирмы принадлежали одной и той же отрасли. Кроме того, считается, что они располагают примерно одинаковыми производственными возможностями и уровнями административного управления. Рассмотренные выше производственные функции носили детерминированный характер и не учитывали влияния случайных возмущений, присущих каждому экономическому явлению. Поэтому в каждое уравнение, параметры которого предстоит оценить, необходимо ввести и случайную переменную е, которая будет отражать воздействие на процесс производства всех тех факторов, которые не вошли в состав производственной функции в явном виде. Таким образом, в общем виде производственную функцию Кобба — Дугласа можно представить как
Мы получили степенную регрессионную модель, оценки параметров которой А, α и β можно найти методом наименьших квадратов, лишь прибегнув предварительно к логарифмическому преобразованию. Тогда для i-го наблюдения имеем
где Qi, Кi и Li — соответственно объемы выпуска, капитальных и трудовых затрат для i-го наблюдения (i = 1, 2, ..., п), а п — объем выборки, т.е. число наблюдений, используемых для получения оценок ln
или
и
Прибегнув к такой форме выражения производственной функции, можно устранить влияние мультиколлинеарности между ln К и ln L. В качестве примера приведем полученную на основе данных о 180 предприятиях, выпускающих верхнюю одежду, модель Кобба — Дугласа:
В скобках указаны значения t-критерия для коэффициентов регрессии уравнения. При этом множественный коэффициент детерминации и расчетное значение статистики F-критерия, соответственно равные r2 = 0,46 и F = 12,7, указывают на значимость полученного уравнения. Оценки параметров α и β функции Кобба — Дугласа равны Система одновременных эконометрических уравнений Систему взаимосвязанных тождеств и регрессионных уравнений, в которой переменные могут одновременно выступать как результирующие в одних уравнениях и как объясняющие в других, принято называть системой одновременных (эконометрических) уравнений. При этом в соотношения могут входить переменные, относящиеся не только к моменту t, но и к предшествующим моментам. Такие переменные называются лаговыми (запаздывающими). Тождества отражают функциональную связь переменных. Техника оценивания параметров системы эконометрических уравнений имеет свои особенности. Это связано с тем, что в регрессионных уравнениях системы независимые переменные и случайные ошибки оказываются коррелированы между собой. Достаточно хорошо изучены статистические свойства и вопросы оценивания систем линейных уравнений. Будем рассматривать линейную модель следующего вида:
где i = 1, 2, ..., G; t = 1, 2, ..., n; yit — значение эндогенной (результирующей) переменной в момент t; xit — значение предопределенной переменной, т.е. экзогенной (объясняющей) переменной в момент t или лаговой эндогенной переменной; uit —случайные возмущения, имеющие нулевые средние. Совокупность равенства (53.60) называется системой одновременных уравнений в структурной форме. Наличие априорных ограничений, связанных, например, с тем, что часть коэффициентов считаются равными нулю, обеспечивает возможность статистического оценивания оставшихся. В матричном виде систему уравнений можно представить как
где В — матрица порядка G х G, состоящая из коэффициентов при текущих значениях эндогенных переменных; Г — матрица порядка G х К, состоящая из коэффициентов экзогенных переменных. yt = (y1t,…, yGti)T, xt = (x1t, … xkt)T, εt = (ε1t, … εGt)T — векторы-столбцы значений соответственно эндогенных и экзогенных переменных, случайных ошибок. Следует отметить, что Mεt = 0; Σ(ε) = MεtεtT =
Среди систем одновременных уравнений наиболее простыми являются рекурсивные системы, для оценивания коэффициентов которых можно использовать метод наименьших квадратов. Систему (53.61) одновременных уравнений называют рекурсивной, если выполняются следующие условия: 1) матрица значений эндогенных переменных
является нижней треугольной матрицей, т.е. βij = 0 при j > 1 и βii = 1; 2) случайные ошибки не зависимы друг от друга, т.е. σii > 0, σij = 0 при i ≠ j, где i, j = 1, 2, ..., G. Отсюда следует, что ковариационная матрица ошибок МεtεtT = Σ(ε) диагональна; 3) каждое ограничение на структурные коэффициенты относится к отдельному уравнению. Процедура оценивания коэффициентов рекурсивной системы с помощью метода наименьших квадратов, примененного к отдельному уравнению, приводит к состоятельным оценкам. В качестве примера рассмотрим ситуацию, которая приводит к рекурсивной системе уравнений. Предположим, что цены на рынке Pt в день t зависят от объема продаж в предыдущий день qt-1, а объем покупок qt в день t зависит от цены товара в день t. Математически систему уравнений можно представить в виде
Случайные возмущения εt и ζt можно считать независимыми. Мы получили рекурсивную систему двух уравнений, причем в правую часть первого уравнения входит предопределенная переменная qt-1, а в правую часть второго — эндогенная переменная Pt. Применение метода наименьших квадратов для получения оценок одновременных уравнений приводит к смещенным и несостоятельным оценкам, поэтому область его применения ограничена рекурсивными системами. Для оценивания систем одновременных уравнений в настоящее время наиболее часто используют двухшаговый метод наименьших квадратов, применяемый к каждому уравнению системы в отдельности, и трехшаговый метод наименьших квадратов, предназначенный для оценивания всей системы в целом. Сущность двухшагового метода состоит в том, что для оценивания параметров структурного уравнения метод наименьших квадратов применяют в два этапа. Он дает состоятельные, но в общем случае смещенные оценки коэффициентов уравнения, является достаточно простым с теоретической точки зрения и удобным для вычисления. Согласно алгоритму трехшагового метода наименьших квадратов, первоначально с целью оценки коэффициентов каждого структурного уравнения применяют двухшаговый метод наименьших квадратов, а затем определяют оценку для ковариационной матрицы случайных возмущений. После этого с целью оценивания коэффициентов всей системы применяется обобщенный метод наименьших квадратов. Пример. Построение эконометрической модели мирового рынка нефти Очевидно, что модель должна отражать взаимосвязь между тремя основными элементами рыночного механизма — спросом, ценой и предложением (эндогенными переменными). В свою очередь состояние указанных элементов в каждый момент можно охарактеризовать с помощью системы объясняющих, экзогенных, переменных. Система включает общехозяйственные и товарно-рыночные показатели. Общехозяйственные показатели отражают экономические процессы, происходящие в мире и отдельных странах, и дают представление о фоне, на котором происходит развитие рынка. Вторая группа показателей отражает явления, которые характерны для рынка нефти. Особый интерес представляют показатели, обладающие опережающим эффектом (временным лагом) по отношению к динамике эндогенных переменных конъюнктуры рынка нефти. При выборе экзогенных переменных учитывалось, что состояние рынка нефти в любой момент определяется не только его внутренними факторами, но и состоянием внешней среды, т.е. общехозяйственной конъюнктурой всего мирового хозяйства, и в первую очередь — динамикой воспроизводственного цикла, уровнем деловой активности в отраслях-потребителях, положением в кредитно-денежной и валютно-финансовой сферах экономики. Завершающим этапом разработки модели исследуемого рынка является ее реализация. На данном этапе математическая модель формируется в общем виде, оцениваются ее параметры, проводится содержательная экономическая интерпретация, выясняются ее статистические и прогностические свойства. При построении модели использовалась система показателей, основанная на ежеквартальных динамических рядах за последние 15 лет, которая характеризует основные стороны рынка нефти в экономическом, временном и географическом аспектах. Проведение корреляционного анализа на этапе предварительной обработки данных позволило ограничить круг используемых показателей (первоначально их было более ста), выбрать для дальнейшего анализа такие, которые отражают воздействие основных факторов на рынок нефти и наиболее тесно связаны с динамикой показателей конъюнктуры. При этом решалась также задача исключения влияния мультиколлинеарности. Модель строилась исходя из предпосылки, что величина спроса играет более активную роль, чем факторы предложения и цены. Рекурсивная модель включает линейные регрессионные уравнения для следующих эндогенных переменных в момент t: y1,t — экспорт нефти из стран ОПЕК; у2,t — добыча нефти в странах ОПЕК; y3,t — цена на нефть легкую аравийскую. В модель вошли предопределенные переменные: у3,t-1 — цена на нефть легкую аравийскую с лагом в 1 квартал; x6,t — поставки нефти на переработку в Японию; х7,t-1 — поставки нефти на переработку в США в момент t-1; x9,t — коммерческие запасы нефти в странах Западной Европы; x10,t-1 — коммерческие запасы нефти в США с лагом в 1 квартал; x12,t — экспорт нефти из бывшего СССР в развитые страны; x20,t-2 — индекс экспортных цен ООН на топливо с лагом в 2 квартала, а x20,t-3 — в 3 квартала; x23,t-1 — загрузка производственных мощностей обрабатывающей промышленности США с лагом в 1 квартал; y1,t / y2,t — показатель, учитывающий дисбаланс на рынке нефти в момент t. Эконометрическая модель конъюнктуры рынка нефти имеет следующий вид:
Анализ статистических характеристик модели показал, что в целом она адекватно описывает рынок нефти: все уравнения значимы, объясняют от 67 до 92% дисперсии эндогенных переменных и характеризуются незначительными отклонениями расчетных значений эндогенных переменных от фактических. Значимость коэффициентов модели проверялась по t-критерию. Расчетные значения tj указаны в скобках под соответствующими коэффициентами. Построенная модель позволяет анализировать различные ситуации развития рынка нефти. Контрольные вопросы 1. Что характеризует парный, частный и множественный коэффициенты корреляции? Сформулируйте их основные свойства. 2. Какие задачи решаются методами регрессионного анализа? 3. В чем состоят отрицательные последствия мультиколлинеарности и как можно избавиться от этого негативного явления? 4. В чем состоит задача компонентного анализа, как интерпретировать главные компоненты и определить их вклад в суммарную дисперсию? 5. Какие задачи решает кластерный анализ? В чем особенности иерархических кластер-процедур? | |
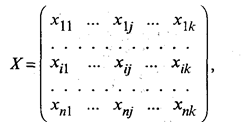
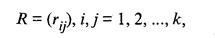
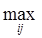 r(xi, хj), 1 ≤ i, j ≤ п, и монотонного убывания r(xi, хj) по мере увеличения ρ(xi, хj), т.е. из ρ(xk, хl) ≥ ρ(xi, хj) должно следовать неравенство r(xk, хl) ≤ ρ(xi, хj).
r(xi, хj), 1 ≤ i, j ≤ п, и монотонного убывания r(xi, хj) по мере увеличения ρ(xi, хj), т.е. из ρ(xk, хl) ≥ ρ(xi, хj) должно следовать неравенство r(xk, хl) ≤ ρ(xi, хj).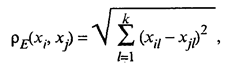 (53.43)
(53.43)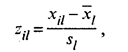
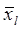 — среднее значение l-го признака;
— среднее значение l-го признака;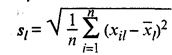 — среднее квадратическое отклонение l-го признака.
— среднее квадратическое отклонение l-го признака.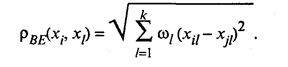 (53.44)
(53.44)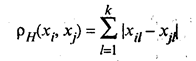 (53.45)
(53.45)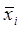 — среднее арифметическое векторных наблюдений группы Si, т.е. «центр тяжести»;
— среднее арифметическое векторных наблюдений группы Si, т.е. «центр тяжести»;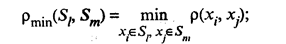 (53.46)
(53.46)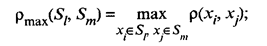 (53.47)
(53.47)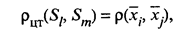 (53.48)
(53.48)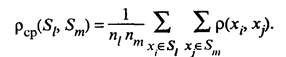 (53.49)
(53.49)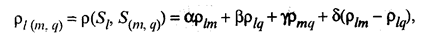 (53.50)
(53.50)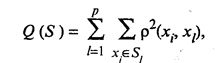 (53.51)
(53.51)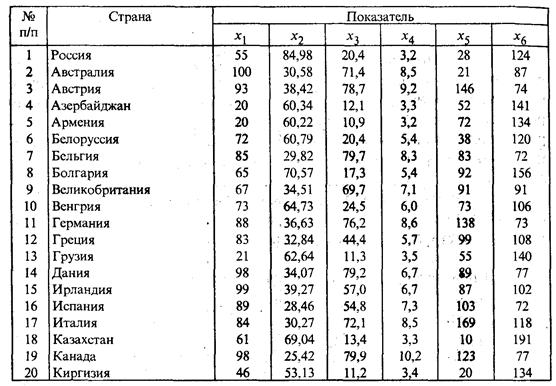

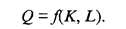
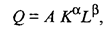 (53.52)
(53.52)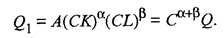 (53.53)
(53.53)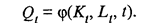
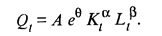 (53.54)
(53.54)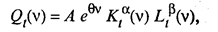 (53.55)
(53.55)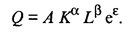 (53.56)
(53.56)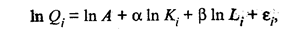 (53.57)
(53.57)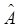 ,
, 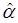 и
и 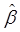 — параметров производственной функции. Относительно εi обычно предполагается, что они взаимно независимы между собой и εi Î N(0, σ ). Исходя из априорных соображений значения α и β должны удовлетворять условиям 0 < α < 1 и 0 < β < 1. Если предположить, что с изменением масштабов производства уровень эффективности остается постоянным, то, приняв, что β = 1 — α, имеем
— параметров производственной функции. Относительно εi обычно предполагается, что они взаимно независимы между собой и εi Î N(0, σ ). Исходя из априорных соображений значения α и β должны удовлетворять условиям 0 < α < 1 и 0 < β < 1. Если предположить, что с изменением масштабов производства уровень эффективности остается постоянным, то, приняв, что β = 1 — α, имеем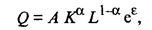 (53.58)
(53.58)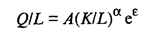
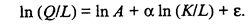 (53.59)
(53.59)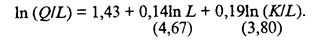
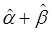 = 1,14 > 1, то можно предположить, что происходит некоторое повышение эффективности по мере расширения масштаба производства. Параметры модели показывают также, что при увеличении капитала К на 1% объем выпуска повышается в среднем на 0,19%, а при увеличении трудовых затрат L на 1% объем выпуска возрастает в среднем на 0,95%.
= 1,14 > 1, то можно предположить, что происходит некоторое повышение эффективности по мере расширения масштаба производства. Параметры модели показывают также, что при увеличении капитала К на 1% объем выпуска повышается в среднем на 0,19%, а при увеличении трудовых затрат L на 1% объем выпуска возрастает в среднем на 0,95%.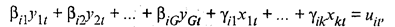 (53.60)
(53.60)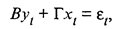 (53.61)
(53.61)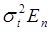 , где En — единичная матрица. Таким образом, если Mεt1εt2 = 0 при t1 ≠ t2 и t1, t2 = 1, 2, ..., п, то случайные ошибки независимы между собой. Если дисперсия ошибки постоянна Mε
, где En — единичная матрица. Таким образом, если Mεt1εt2 = 0 при t1 ≠ t2 и t1, t2 = 1, 2, ..., п, то случайные ошибки независимы между собой. Если дисперсия ошибки постоянна Mε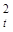 =
= 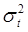 =
= 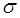 2 и не зависит от t и хt, то это свидетельствует о гомоскедастичности остатков. Условием гетероскедастичности является зависимость значений Мε
2 и не зависит от t и хt, то это свидетельствует о гомоскедастичности остатков. Условием гетероскедастичности является зависимость значений Мε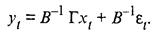 (53.62)
(53.62)