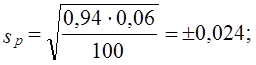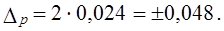| Главная » Учебно-методические материалы » СТАТИСТИКА » Общая теория статистики: учебник. Под ред. Елисеевой И.И. |
| 23.01.2012, 13:36 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
7.1. Причины применения выборочного наблюдения. Дискриптивная статистика и статистический выводВ главе 2 отмечалось, что статистика далеко не всегда имеет дело с данными сплошного наблюдения. Из всех видов несплошного наблюдения главным является выборочное наблюдение, так как только выборочный метод имеет статистико-математическое обоснование распространения данных, полученных по выборке, на всю совокупность. Причин использования выборочного метода несколько. Во-первых, как это ни парадоксально, это повышение точности данных; уменьшение числа единиц наблюдения в выборке резко снижает ошибки регистрации. Правда, за счет неполноты охвата единиц возникает ошибка репрезентативности, т. е. представительности выборочных данных. Но даже взятые вместе ошибка наблюдения для выборки плюс ошибка репрезентативности обеспечивают большую точность выборочных данных по сравнению с массовым сплошным наблюдением. При ограничении объема работы можно привлечь более квалифицированных исполнителей (интервьюеров, счетчиков-регистраторов). Это положительно сказывается на качестве данных выборочного обследования. Во-вторых, обращение к выборкам обеспечивает экономию материальных, трудовых, финансовых ресурсов и времени. Например, для составления баланса, денежных доходов и расходов населения, для изучения денежного обращения, выявления дифференциации населения по уровню жизни, определения черты бедности и т. д. необходимы данные о бюджетах домохозяйств. Сбор этих данных осуществляется государственной статистикой, но один статистик в состоянии курировать ежедневные записи доходов, расходов, потребления не более чем в 20-25 домохозяйствах. Если бы решили собирать данные о бюджетах всех домохозяйств, то только для этой цели (не учитывая потребности последующей обработки) потребовалось бы примернб два миллиона статистиков. Так что использование выборочного наблюдения является единственным экономически выгодным решением, тем более что по результатам изучения сравнительно небольшой части можно получить с достаточно высокой степенью уверенности данные о всей совокупности. Подобная ситуация возникает и при аудиторских проверках крупных фирм, когда вместо детального изучения каждого платежного документа ограничиваются анализом выборки документов, и в других областях применения статистики. В-третьих, без выборки не обойтись, когда наблюдение связано с порчей наблюдаемых объектов. Это относится прежде всего к изучению качества продукции, которое основано на испытаниях образцов на вибрацию, упругость, разрыв и т.д. Всю продукцию, конечно же, таким испытаниям не подвергают, только отобранные образцы. То же можно сказать об исследовании молока на жирность, зерна -на содержание белка, влажность, чистоту и всхожесть семян, электрических лампочек - на длительность горения и т.д. На выборках основаны маркетинговые исследования, оценки качества поставок. Практика применения выборочного метода очень разнообразна. Иногда, проведя сплошное наблюдение, применяют выборочный метод при разработке данных: отбирают часть данных для более подробной разработки по расширенной программе. Так поступают, например, при разработке данных переписи населения о составе и типах семей. Нередко в процессе сбора данных применяют совместно сплошное и несплошное наблюдение. При переписях населения в нашей стране (1959, 1970, 1979 гг.) собирались сведения о каждом лице по 11 признакам, а 25% населения давали более подробную информацию (18 вопросов). Выборки используются при опросах общественного мнения, при выяснении потребительских предпочтений, формировании доходов и расходов населения, при определении урожайности сельскохозяйственных культур и продуктивности скота. С 20-х гг. нашего века выборочный метод стал использоваться для контроля и анализа качества продукции. Сейчас методы статистической выборки все шире внедряются в самые различные области. В 1994 г. в Российской Федерации была проведена 5%-ная микроперепись населения с целью уточнения демографического и социального состава населения, уровня благосостояния, включая жилищные условия, источники дохода и др. Та совокупность, из которой производится отбор, называется генеральной совокупностью; отобранные данные составляют выборочную совокупность. Эти данные представляют интерес постольку, поскольку дают основание для суждений б параметрах и свойствах генеральной совокупности. Таким образом, выборочный метод обладает следующими достоинствами: • относительно небольшие (по сравнению со Сплошным наблюдением) материальные, трудовые и стоимостные затраты на сбор данных (включая затраты на планирование и формирование выборки); • оперативность получения результатов; • широкая область применения; • высокая достоверность результатов. Все эти достоинства проявляются лишь при условии правильного решения проблем выборочного обследования. К ним относятся: 1) определение границ генеральной совокупности; 2) разработка программы наблюдения и инструкций; 3) определение основы для проведения выборки - списка единиц генеральной совокупности, сведений об их размещении и т.д.; 4) уствновновление допустимого размера погрешности и определение объема выборки; 5) определение вида выборочного наблюдения; 6) установление сроков проведения наблюдения; 7) определение потребности в кадрах для проведения выборочного наблюдения, их подготовка; 8) оценка точности и достоверности данных выборки, определение порядка их распространения на генеральную совокупность. Представление о статистических данных как о выборочных может относиться не только к собственно выборке, но и к данным сплошного наблюдения, которые иногда рассматриваются как выборка из всех возможных реализации изучаемого процесса. Это имеет смысл в случае малого числа единиц совокупности. Кроме того, трактовка данных как выборочных используется применительно к результатам эксперимента, которые рассматриваются как некая выборка из потенциально бесконечного числа повторений экспериментальных наблюдений. Трактовка данных как выборочных является основой деления статистики на описательную (дискриптивную) и выводную. Методы описательной статистики включают сбор данных по всем единицам изучаемой совокупности, их обработку, получение сводных показателей, которые являются характеристиками только наблюдаемой совокупности. Например, если наша задача состоит в изучении успеваемости группы студентов, включающей 25 человек, вычисленный средний балл по этой группе, процент отличных оценок и т. д. являются описаниями этой совокупности. Если же мы будем рассматривать эту группу студентов с точки зрения оценки успеваемости всех студентов данного колледжа или университета, то эта группа предстанет как выборка из общего числа студентов. В этом случае средний балл для группы будет являться оценкой средней успеваемости студентов колледжа в целом. Генеральная совокупность может быть реальной, а может быть гипотетической, включающей случаи, которые реально не существуют, например все возможные результаты эксперимента. В выводной статистике принято строго различать параметры и свойства генеральной совокупности и их оценки по данным выборки. С этой целью принятаследующая система обозначений: генеральные параметры обозначаются греческими буквами, выборочные показатели, которые рассматриваются как оценки генеральных параметров, обозначаются латинскими буквами. Например,
Объем генеральной совокупности обозначают N, объем выборочной совокупности - k. Выборочные оценки отличаются от генеральных параметров за счет ошибки наблюдения и ошибки выборки:
Подводя итоги, можно сказать, что описательная статистика является инструментом описания совокупности, по которой у нас полностью имеются исходные данные. Метод статистического вывода позволяет по данным выборок делать заключение о более большой совокупности, по которой мы не имеем исчерпывающих наблюдений. 7.2 Способы отбора, обеспечивающие репрезентативность выборки. Виды выборкиДля того чтобы можно было по выборке делать вывод о свойствах генеральной совокупности, выборка должна быть репрезентативной (представительной), т. е. она должна полно и адекватно представлять свойства генеральной совокупности. Репрезентативность выборки может быть обеспечена только при объективности отбора данных. Выборочная совокупность формируется по принципу массовых вероятностных процессов без каких бы то ни было исключений от принятой схемы отбора; необходимо обеспечить относительную однородность выборочной совокупности или ее разделение на однородные группы единиц. При формировании выборочной совокупности должно быть дано четкое определение единицы отбора. Желателен приблизительно одинаковый размер единиц отбора, причем результаты будут тем точнее, чем меньше единица отбора. Возможны три способа отбора: случайный отбор, отбор единиц по определенной схеме, сочетание первого и второго способов. Если отбор в соответствии с принятой схемой проводится из генеральной совокупности, предварительно разделенной на типы (слои или страты), то такая выборка называется типической (или расслоенной, или стратифицированной, или районированной). Еще одно деление выборки по видам определяется тем, что является единицей отбора: единица наблюдения или серия единиц (иногда используют термин «гнездо»). В последнем случае выборка называется серийной, или гнездовой. На практике часто используется сочетание типической выборки с отбором сериями. В математической статистике, обсуждая проблему отбора данных, обязательно вводят деление выборки на повторную и бесповторную. Первая соответствует схеме возвратного шара, вторая - безвозвратного (при рассмотрении процесса отбора данных на примере отбора шаров разного цвета из урны). В социально-экономической статистике нет смысла применять повторную выборку, поэтому, как правило, имеется в виду бесповторный отбор. Если выборка производится по схеме возвращенного шара, то вероятность попадания любой единицы в выборку равна MN, и она остается той же самой на протяжении всей процедуры отбора. Если выборка производится по схеме невозвращенного шара, то вероятность попадания единицы в выборку изменяется от Так как социально-экономические объекты имеют сложную структуру, то выборку бывает довольно трудно организовать. Например, чтобы провести отбор домохозяйств при изучении потребления населением крупного города, легче произвести сначала отбор территориальных ячеек, жилых домов, потом квартир или домохозяйств, затем респондента. Такая выборка называется многоступенчатой. На каждой ступени используются разные единицы отбора: более крупные - на начальных ступенях, на последней ступени единица отбора совпадает с единицей наблюдения. Еще один вид выборочного наблюдения - многофазовая выборка. Такая выборка включает определенное количество фаз, каждая из которых отличается подробностью программы наблюдения. Например, 25% всей генеральной совокупности обследуются по краткой программе, каждая 4-я единица из этой выборки обследуется по более полной программе и т.д. При любом виде выборки отбор единиц производится тремя отмеченными способами. Рассмотрим процедуру случайного отбора. Прежде всего составляется список единиц совокупности, в котором каждой единице присваивается цифровой код (номер или метка). Затем производится жеребьевка. Закладываются в барабан шары с соответствующими номерами, они перемешиваются и проводится отбор шаров. Выпавшие номера соответствуют единицам, попавшим в выборку; число номеров равно запланированному объему выборки. Отбор жеребьевкой может быть подвержен смещениям, вызванным недостатками техники (качеством шаров, барабана) и другими причинами. Более надежен с точки зрения объективности отбор по таблице случайных чисел. Такая таблица содержит серии цифр, чередующихся случайным образом, отобранных путем электронных сигналов. Так как мы пользуемся десятичной цифровой системой О, 1,2, ..., 9, вероятность появления любой цифры равна 1/10. Следовательно, если бы нужно было создать таблицу случайных чисел, включающую 500 знаков, то из них около 50 были бы 0, столько же - 1 и т.д. Ввиду того, что каждая цифра и их последовательность являются случайными, можно использовать таблицу, перемещаясь либо по ее вертикали, либо по горизонтали. Цифры сгруппированы по 5 для лучшей обозримости таблицы и пользования ею (см. Приложение, табл. 7). Предположим, что нам нужно из 9540 студентов университета произвести 5%-ную выборку: n = 5% • -N = 477 студентов. Ввиду того, что объем генеральной совокупности выражается четырехзначным числом, код каждого студента должен быть четырехзначным: от 0001 - для первого студента до 9540 - для последнего студента в списке. Чтобы произвести отбор по таблице случайных чисел, нужно выбрать начальную точку: можно закрыть глаза и поставить наугад точку в таблице карандашом. Предположим, мы попали в 13-ю строку в 1-й столбец (табл. 7.1). Таблица 7.1 Пример использования таблицы случайных чисел
Следовательно, единица с номером 9082 является первой в выборке. Если двигаться по строке, то единица с номером 2602 будет второй, 8088 - третьей, 9259 - четвертой. Следующий код 9610 пропускаем, так как у нас нет студента с таким номером. Далее в выборку попадают номера 4277, 2605, 6176, 8730, 4117, 7212, 1791, 5296, 5919, 0305, 1018. Код 9797 пропускается. Следующие отобранные номера 7868, 0161, 3747, 9526, 8413, 7725 и т.д. Процедура продолжается, пока число отобранных номеров не составит требуемый объем выборки (n = 477). Часто используется отбор по какой-либо схеме (так называемая направленная выборка). Схема отбора принимается такой, чтобы отразить основные свойства и пропорции генеральной совокупности. Простейший способ: по спискам единиц генеральной совокупности, составленным так, чтобы упорядочивание единиц было бы не связано с изучаемыми свойствами, проводится механический отбор единиц с шагом, равным N : п. Обычно отбор начинают не с первой единицы, а отступив полшага, чтобы уменьшить возможность смещения выборки. Частота появления единиц с теми или иными особенностями, например студентов с тем или иным уровнем успеваемости, живущих в общежитии, и т.д. будет определяться той структурой, которая сложилась в генеральной совокупности. Для большей уверенности в том, что выборка отразит структуру генеральной совокупности, последняя подразделяется на типы (стра-ты или районы), и проводится случайный или механический отбор из каждого типа (района, страта). Общее число единиц, отобранных из разных типов, должно соответствовать объему выборки. Особые трудности возникают, когда нет списка единиц, а отбор нужно произвести либо на местности, либо из образцов продукции на складе готовой продукции. В этих случаях важно детально разработать схему ориентации на местности и схему отбора и следовать ей, не допуская отклонений. Например, счетчик имеет указание двигаться от определенной автобусной остановки на север по четной стороне улицы и, отсчитав два дома от первого угла, войти в третий и провести опрос в каждом 5-м жилом помещении. Неукоснительное следование принятой схеме обеспечивает выполнение главного условия формирования репрезентативной выборки - объективности отбора единиц. От случайной выборки следует отличать квотный отбор, когда выборка конструируется из единиц определенных категорий (квот), которые должны быть представлены в заданных пропорциях. Например, при опросе покупателей универмага может быть запланировано провести отбор 150 респондентов, в том числе 90 женщин, из них 25 - девушек, 20 - молодых женщин с маленькими детьми, 35 -женщин среднего возраста, одетых в деловой костюм, 10 -женщин 50 лет и старше; кроме того, планировался опрос 70 мужчин, из них 25 - подростков и юношей, 20 - молодых мужчин с детьми, 15 -мужчин. Которые одеты в костюмы, 10 - мужчин, одетых в спортивную одежду. Для определения потребительских ориентации и предпочтений такая выборка, может быть, и хороша, но если мы захотим по ней установить среднюю сумму покупок, их структуру, мы получим непредставительные результаты. Это происходит потому, что квотная выборка нацелена на отбор определенных категорий. Выборка может быть нерепрезентативной, даже если она формируется в соответствии с известными пропорциями генеральной совокупности, но отбор проводится без какой-либо схемы - единицы набираются как угодно, лишь бы обеспечить соотношение их категорий в тех же пропорциях, что и в генеральной совокупности (например, соотношение мужчин и женщин, респондентов в возрасте моложе и старше трудоспособного и в трудоспособном и т.д.). Эти замечания должны предостеречь вас от подобных подходов к формированию выборки и еще раз подчеркнуть необходимость объективного отбора. 7.3. Ошибка выборкиВсе ошибки выборочного наблюдения подразделяются на ошибки выборки (случайные); ошибки, вызванные отклонением от схемы отбора (неслучайные); ошибки наблюдения (случайные и неслучайные).Плохо, когда ошибка выборки превышает допустимый размер погрешности, но слишком высокая точность также подозрительна и, как правило, свидетельствует об ошибках отбора. Ошибки отбора приводят к неслучайным ошибкам. Так бывает, если объективный отбор подменяется «удобной» выборкой. Например, когда появляются добровольные респонденты - те, кто сами предлагают, чтобы их опросили. Очевидно, что характеристики таких добровольцев и недобровольцев могут быть отличны и это приведет к ошибочному заключению о генеральной совокупности. Такая же опасность возникает при замене по какой-либо причине единиц, попавших в выборку, другими единицами (например, вместо отобранного домохозяйства, где в момент прихода интервьюера никто не открыл дверь, был проведен опрос в соседней квартире; или интервьюер встретил решительный отказ участвовать в опросе и был вынужден пойти на замену домохозяйства). Как отмечает социолог В. И. Паниотто, систематические ошибки представляют собой некоторое постоянное смещение, которое не уменьшается с увеличением числа опрошенных и вызвано недостатками и просчетами в системе отбора респондентов. Если, например, для изучения общественного мнения жителей города в архитектурном управлении получить сведения о жилом фонде и из всех имеющихся в городе квартир отобрать случайным образом 400 квартир, а затем предложить интервьюерам опросить всех, кого они застанут в момент посещения в этих квартирах, то полученные данные не будут репрезентативны. Допущена систематическая ошибка: более подвижная часть населения попадает в выборку в меньшей пропорции, а менее подвижная - в большей пропорции, чем в генеральной совокупности. Пенсионеров, например, можно чаще застать дома, чем студентов-вечерников. При увеличении выборки эта ошибка не устраняется: если мы проведем опрос в 800 квартирах или даже во всех квартирах города (сплошной опрос), то полученные данные будут репрезентативны для населения, находящегося дома в момент прихода интервьюера, а не для всех жителей города. Неслучайные ошибки могут возникнуть из-за методов сбора данных: вопросов, слишком болезненных для опрашиваемых (об отношении к Властям, если опрашиваются беженцы или пострадавшие от стихийных бедствий и т.д.) или формы задания вопроса (очень трудно, чтобы всем было все понятно), или времени опроса (например, на вопрос молодым родителям, не жалеют ли они о том, что у них есть дети, можно получить разное распределение ответов в зависимости от того, проводился ли опрос долгим зимним вечером, когда все утомлены приготовлением уроков, простудами и т.д., или прекрасным летним днем, когда дети находятся на даче, в оздоровительном лагере). Случайные ошибки - те, которые изменяются по вероятностным законам. К случайным относится ошибка выборки. Ошибка выборки или, иначе говоря, ошибка репрезентативности - это разница между значением показателя, полученного по выборке, и генеральным параметром. Так, ошибка репрезентативности выборочной средней равна Если представить, что было проведено бесконечное число выборок равного объема из одной и той же генеральной совокупности, to показатели отдельных выборок образовали бы ряд возможных значений: выборочных средних величин х̅1, х̅2, ..., относительных величин р1, р2, р3 ..., дисперсий s21, s22, s23, … и т.д. Каждая Выборка имеет свою ошибку репрезентативности. Следовательно, можно построить ряды распределения выборок по величине ошибки репрезентативности для каждого показателя: для средней, относительной величины и т.д. В таких распределениях улавливается тенденция к концентрации ошибок около центрального значения. Число выборок с той или иной величиной ошибки репрезентативности может быть симметрично или асимметрично относительно этого центрального значения. При бесконечно боль-цюм числе выборок получится кривая частот, которая представляет кривую выборочного распределения. Свойства таких распределений используются для получения статистических заключений, установления вероятности той или иной величины ошибки репрезентативности. Рассмотрим выборочное распределение средней величины. Такое распределение будет являться нормальным илу приближаться к нему •flo мере увеличения объема выборки, независимо от того, имеет или |нет нормальное распределение та генеральная совокупность, из ^которой взятывыборки. С увеличением числа выборок средняя для tcex выборок будет приближаться к генеральной средней. По выборочному распределению может быть рассчитана средняя квадра-тическая ошибка репрезентативности:
Среднее квадратическое отклонение выборочных средних от генеральной средней называется средней ошибкой выборочной средней:
Поскольку, как правило, генеральная средняя и неизвестна, этой формулой нельзя воспользоваться. Кроме того, в социально-экономических исследованиях из одной и той же совокупности выборки не проводятся многократно. Используют следующее соотношение: квадрат средней ошибки (дисперсия выборочных средних) прямо пропорционален дисперсии признака х в генеральной совокупности о и обратно пропорционален объему выборки п: Соответственно средняя ошибка выборочной средней равна: Следовательно, средняя ошибка выборки тем больше, чем больше вариация в генеральной совокупности, и тем меньше, чем больше объем выборки. Таким образом, можно утверждать, что отклонение выборочной средней х от генеральной средней ц в среднем равно ±s, . Ошибка конкретной выборки может принимать различные значения, но отношение ее к средней ошибке практически не превышает ±3, если величина п достаточно большая (и > 100). Отношение ошибки конкретной выборки к средней квадратической ошибке называется нормированным отклонением и обозначается как:
Распределение нормированного отклонения выборочной средней <уг генеральной средней при численности выборки п —> оо определяется уравнением Лапласа-Гаусса:
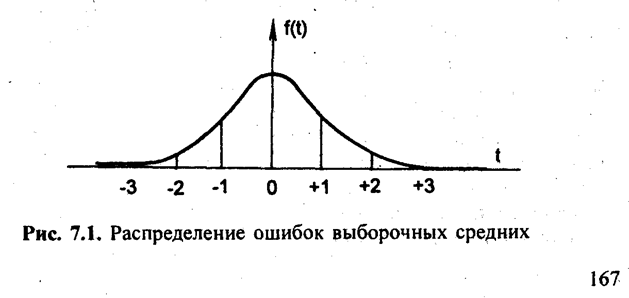
натами, соответствующими t1, и t2 ко всей площади кривой. Вся площадь под кривой нормального распределения вероятностей принимается за единицу. Уравнение Лапласа - Гаусса предполагает непрерывное изменение t и неограниченное возрастание п. Поэтому площадь нормальной кривой, заключенную между ординатами t1 и t2, определяют, интегрируя функцию (7.7). Имеются таблицы, которые содержат значения вероятностей для нормированных отклонений t или для интервалов от t1 до t2. Одна из таких таблиц приведена в приложении «Значение интеграла вероятностей». Эта таблица содержит пропорциональные доли площадей, заключенных между ординатами, соответствующими ± t. Зная нормированное отклонение t, можно определить вероятность или на основе определенной вероятности установить величину t. На пересечении строк и граф таблицы находится значение вероятности F(t), соответствующее данному значению t. Для краткости записи в таблице приводятся только десятичные знаки вероятности, следовательно, к табличному значению F(t) надо приписывать ноль целых. Например, чтобы определить, какая вероятность соответствует t= 1,96, надо взять строку 1,9 и графу 6 и на их пересечении прочитать значение вероятности, добавив перед первым знаком ноль целых. Если t = 1,96, то F(f)= 0,9500. По мере увеличения t (уже при t = ±3) значение интеграла вероятностей приближается к единице. Чем шире пределы t, тем большая площадь под кривой охватывается ординатами, восстановленными из соответствующих значений t. Поскольку вероятность — это отношение части площади под кривой, заключенной между ординатами, ко всей площади, соответственно возрастает и вероятность. Распределение ошибок выборочных средних имеет характер нормального распределения или приближается к нему даже в случаях, когда генеральная совокупность имеет иную форму распределения. Из формулы (7.5) следует, что отклонение выборочной средней от генеральной средней равно:
Нормированное отклонение / может быть установлено по таблице «Значение интеграла вероятностей». Для этого необходимо принять определенный уровень вероятности суждения о точности данной выборки. Вероятность, которая принимается при расчете ошибки выборочной характеристики, называют доверительной. Чаще всего принимают доверительную вероятность равной 0,95, 0,954, 0,997 или даже 0,999. Доверительный уровень вероятности 0,95 означает, что только, в 5 случаях из 100 ошибка может выйти за установленные границы; вероятности 0,954 - в 46 случаях из 1000, при 0,997 - в 3 случаях, а при 0,999 - в 1 случае из 1000. Чтобы вычислить ошибку выборки при принятой доверительной вероятности, нужно рассчитать величину средней ошибки sx. Формула для ее определения (7,4) включает дисперсию признака в генеральной совокупности σ2, которая, как правило, неизвестна. Может быть определена только выборочная дисперсия s2. Доказано, что соотношение между σ2 и s2 определяется следующим равенством:
Если п велико, то сомножитель п/(п - 1) ≈ 1 и можно принять выборочную дисперсию в качестве оценки величины генеральной дисперсии. Подставив выражение (7.10) в формулу средней ошибки выборочной средней, получим:
Рассмотрим пример. Для определения скорости расчетов с кредиторами предприятий одного треста была проведена случайная выборка 50 платежных документов, по которым средний срок перечисления денег оказался равен 28,2 дня со стандартным отклонением 5,4 дня. Определим средний срок прохождения всех платежей в течение данного года с доверительной вероятностью F(t) = 0,95. Тогда t = 1,96; скорректированная дисперсия
средняя ошибка выборки
Отклонение выборочной средней от генеральной с вероятностью 0,95 составит ∆x = 1,96 ∙ 0,77 = ± 1,51 дня. ∆ называется доверительной ошибкой выборки или предельной ошибкой выборки. Рассчитав величину ∆, мы можем записать следующее неравенство: 28,2 - 1,51 £ μ £ 28,2 + 1,51; 26,7 дня £ μ £ 29,7 дня. Таким образом, с вероятностью 0,95 можно утверждать, что средняя продолжительность расчетов предприятия данного треста с кредиторами составляет не менее 26,7 дня и не более 29,7 дня. Ошибка выборки для выборочной относительной величины (доли) определяется аналогично. Дисперсия относительной величины по данным выборки
где р - доля тех или иных единиц в выборке. Выражение (7.13) получено в соответствии с обычной формулой дисперсии. Поскольку имеется в виду альтернативная или дихотомическая переменная, обозначим ее значение в одной категории единиц О, в другой - 1. Тогда среднее значение переменной составит:
квадрат отклонения от средней
что соответствует выражению (7.13). Средняя ошибка выборочной доли
Предельная ошибка выборочной доли с принятой доверительной вероятностью имеет вид: Рассмотрим пример. По данным выборочного изучения 100 платежных документов предприятий одного треста оказалось, что в б случаях сроки расчетов с кредиторами были превышены. С вероятностью 0,954 требуется установить доверительный интервал доли платежных документов треста без нарушения сроков:
Генеральная доля платежных документов π, не выходящих за установленные сроки, с вероятностью 0,954 находится в интервале 0,892 £ π £ 0,988, или 89,2% £ π £ 98,8%. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
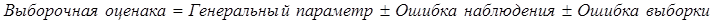
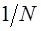 - для первой отбираемой единицы, до
- для первой отбираемой единицы, до 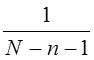 - для последней.
- для последней.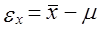 , выборочной относительной величины
, выборочной относительной величины 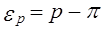 , дисперсии
, дисперсии 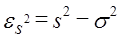 , коэффициента корреляции
, коэффициента корреляции 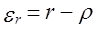 .
.







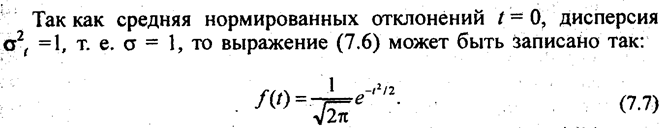


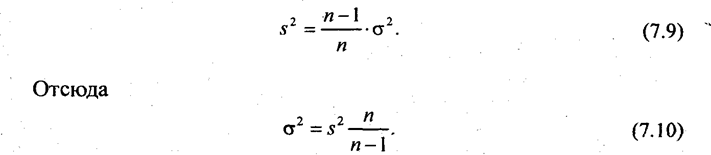
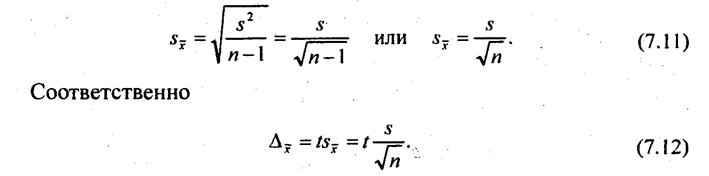
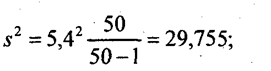
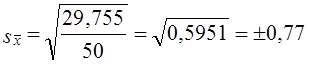 дня.
дня.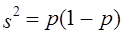 , (7.13)
, (7.13)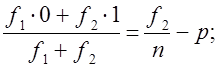
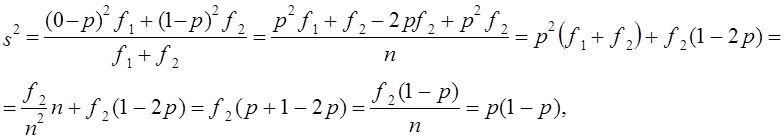
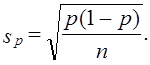 (7.14)
(7.14)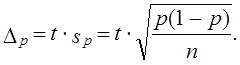 (7.15)
(7.15)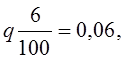 или 6%, р = 0,94;
или 6%, р = 0,94;