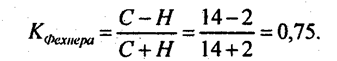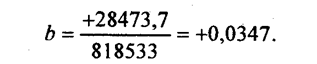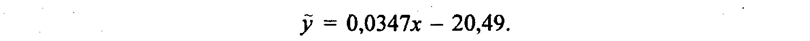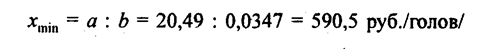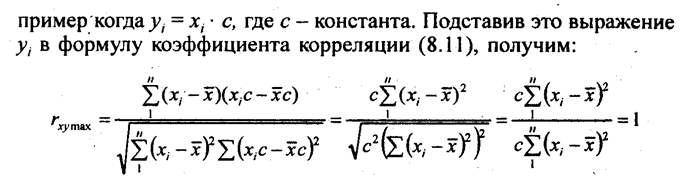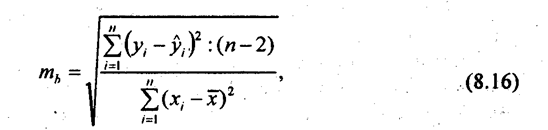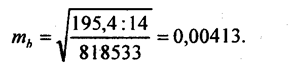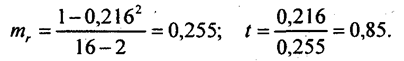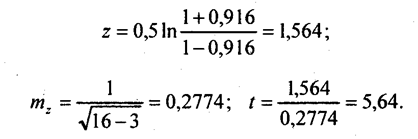| Главная » Учебно-методические материалы » СТАТИСТИКА » Общая теория статистики: учебник. Под ред. Елисеевой И.И. |
| 23.01.2012, 16:51 | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
8.1. Понятие о статистической и корреляционной связиСовременная наука исходит из взаимосвязи всех явлений природы и общества. Объем продукции предприятия связан с численностью работников, мощностью двигателей, стоимостью производственных фондов и еще многими признаками. Невозможно управлять явлениями, предсказывать их развитие без изучения характера, силы и других особенностей связей. Поэтому методы исследования, измерения связей составляют чрезвычайно важную часть методологии научного исследования, в том числе и статистического. Различают два типа связей между различными явлениями и их признаками: функциональную или жестко детерминированную, с одной стороны, и статистическую или стохастически детерминированную- с другой. Строго определить различие этих типов связи можно тогда, когда они получают математическую формулировку. Для простоты будем говорить о связи двух явлений или двух признаков, математически отображаемой в форме уравнения связи двух переменных. Если с изменением значения одной из переменных вторая изменяется строго определенным образом, т.е. значению одной переменной обязательно соответствует одно или несколько точно заданных значений другой переменной, связь между ними является функциональной. Нередко говорят о строгом соответствии лишь одного значения второй из переменных каждому значению первой из них, но это неверно. Например, связь между у и х является строго функциональной, если Функциональная связь двух величин возможна лишь при условии, что вторая из них зависит только от первой и ни от чего более. В реальной природе (и тем более в обществе) таких связей нет; они являются лишь абстракциями, полезными и необходимыми при анализе явлений, но упрощающими реальность. Функциональная зависимость данной величины у от многих факторов х1, х2, ..., хn возможна только в том случае, если величина y всегда зависит только от перечисленного набора факторов x1, х2 ..., хk и ни от чего более. Между тем все явления и процессы безграничного реального мира связаны между собой, и нет такого конечного числа переменных k, которые абсолютно полно определяли бы собою зависимую величину y. Следовательно, множественная функциональная зависимость переменных есть тоже абстракция, упрощающая реальность. Однако такие науки, как механика, электротехника, акустика, политическая экономия и другие, успешно используют представление связей как функциональных не только в аналитических целях, но нередко и в целях прогнозирования. Это возможно потому, что в простых системах интересующая нас переменная величина зависит в основном (скажем, на 99% или даже на 99,99%) от немногих других переменных или только от одной переменной. То есть связь в такой несложной системе является хотя и не абсолютно функциональной, но практически очень близкой к таковой. Например, длина года (период обращения Земли вокруг Солнца) почти функционально зависит только от массы Солнца и расстояния Земли от него. На самом деле она зависит в очень слабой степени и от масс, и расстояния других планет от Земли, но вносимые ими (и тем более в миллионы раз более далекими звездами) искажения функциональной связи для всех практических целей, кроме космонавтики, пренебрежимо малы. Стохастически детерминированная связь не имеет ограничений и условий, присущих функциональной связи. Если с изменением значения одной из переменных вторая может в определенных пределах принимать любые значения с некоторыми вероятностями, но ее среднее значение или иные статистические (массовые) характеристики изменяются по определенному закону - связь является статистической. Иными словами, при статистической связи разным значениям одной переменной соответствуют разные распределения значений другой переменной. В настоящее время наука не знает более широкого определения связи. Все связи, которые могут быть измерены и выражены численно, подходят под определение «статистические связи», в том числе и функциональные. Последние представляют собой частный случай статистических связей, когда значениям одной переменной соответствуют «распределения» значений второй, состоящие из одного или нескольких значений и имеющие вероятность, равную ' единице. Конечно, качественное различие действительно вероятностных распределений и отдельных значений, имеющих вероятность единицы (достоверных), настолько велико, что хотя функциональные связи и подходят в широком смысле под определение статистической связи, все же с полным основанием можно говорить о двух типах связей. Корреляционной связью называют важнейший частный случай статистической связи, состоящий в том, что разным значениям одной переменной соответствуют различные средние значения другой. С изменением значения признака х закономерным образом изменяется среднее значение признака у; в то время как в каждом отдельном случае значение признака у (с различными вероятностями) может принимать множество различных значений. Если же С изменением значения признака х среднее значение признака у не изменяется закономерным образом, но закономерно изменяется другая статистическая характеристика (показатели вариации, асимметрии, эксцесса и т.п.), то связь является не корреляционной, хотя и статистической. Статистическая связь между двумя признаками (переменными величинами) предполагает, что каждый из них имеет случайную вариацию индивидуальных значений относительно средней величины. Если же такую вариацию имеет лишь один из признаков, а значения другого являются жестко детерминированными, то говорят лишь о регрессии, но не о статистической (тем более корреляционной) связи. Например, при анализе динамических рядов'можно измерять регрессию уровней ряда урожайности (имеющих случайную колеблемость) на номера лет. Но нельзя говорить о корреляции между ними и применять показатели корреляции с соответствующей им интерпретацией (см. гл. 9). Само слово корреляция ввел в употребление в статистику английский биолог и статистик Френсис Гальтон в конце XIX в. Тогда оно писалось как «corelation» (соответствие), но не просто «связь» (relation), а «как бы связь», т. е. связь, но не в привычной в то время функциональной форме. В науке вообще, а именно в палеонтологии, термин «корреляция» применил еще раньше, в конце XYI1I в., знаменитый французский палеонтолог (специалист по ископаемым останкам животных и растений прошлых эпох) Жорж Кювье. Он ввел даже «закон корреляции» частей и органов животных. «Закон корреляции» помогает восстановить по найденным в раскопках черепу, костям и т. д. облик всего животного и его место в системе: если череп с рогами, то это было травоядное животное, а его конечности имели копыта; если же лапа с когтями - то хищное животное без рогов, но с крупными клыками. Известен следующий рассказ о Кювье и «законе корреляции». В дни университетского праздника студенты решили подшутить над профессором Кювье. Они вырядили одного из студентов в козлиную шкуру с рогами и копытами и подсадили его в окно спальни Кювье. Ряженый загремел копытами и завопил: «Я тебя съем!». Кювье проснулся, увидел силуэт с рогами и спокойно отвечал: «Если у тебя рога и копыта, то по закону корреляции ты травоядное, и съесть меня не можешь. А за то, что не знаешь закона корреляции, получишь двойку!». Корреляционная связь между признаками может возникать разными путями. Важнейший путь - причинная зависимость результативного признака (его вариации) от вариации факторного признака. Например, признак х - балл оценки плодородия почв, признак у -урожайность сельскохозяйственной культуры. Здесь совершенно ясно логически, какой признак выступает как независимая переменная (фактор) х, какой - как зависимая переменная (результат) у. Совершенно иная интерпретация необходима при изучении корреляционной связи между двумя следствиями общей причины. Известен классический пример, приведенный крупнейшим статистиком России начала XX в. А. А. Чупровым: если в качестве признака х взять число пожарных команд в городе, а за признака - сумму убытков за год в городе от пожаров, то между признаками х и у в совокупности городов России существенна прямая корреляция; в среднем, чем больше пожарников в городе, тем больше и убытков от пожаров! Уж не занимались ли пожарники поджигательством из боязни потерять работу? Но дело в другом. Данную корреляцию нельзя интерпретировать как связь причины и следствия; оба признака - следствия общей причины - размера города. Вполне логично, что в крупных городах больше пожарных частей, но больше и пожаров, и убытков от них за год, чём в мелких городах. Третий путь возникновения корреляции - взаимосвязь признаков, каждый из которых и причина, и следствие. Такова, например, корреляция между уровнями производительности труда рабочих и уровнем оплаты 1 ч труда (тарифной ставкой). С одной стороны, уровень зарплаты - следствие производительности труда: чем она выше, тем выше и оплата. Но с другой стороны, установленные тарифные ставки и расценки играют стимулирующую роль: при правильной системе оплаты они выступают в качестве фактора, от которого зависит производительность труда. В такой системе признаков допустимы обе постановки задачи; каждый признак может выступать и в роли независимой переменной х, и в качестве зависимой переменной у. 8.2. Условия применения и ограничения корреляционно-регрессивного методаПоскольку корреляционная связь является статистической, первым условием возможности ее изучения является общее условие всякого статистического исследования: наличие данных по достаточно большой совокупности явлений. По отдельным явлениям можно получить совершенно превратное представление о связи признаков, ибо в каждом отдельном явлении значения признаков кроме закономерной составляющей имеют случайное отклонение (вариацию). Например, сравнивая два хозяйства, одно из которых имеет лучшее качество почв, по уровню урожайности, можно обнаружить, что урожайность выше в хозяйстве с худшими почвами. Ведь урожайность зависит от сотен факторов и при том же самом качестве почв может быть и выше, и ниже. Но если сравнивать большое число хозяйств с лучшими почвами и большое число - с худшими, то средняя урожайность в первой группе окажется выше и станет возможным измерить достаточно точно параметры корреляционной связи. Какое именно число явлений достаточно для анализа корреляционной и вообще статистической связи, зависит от цели анализа, требуемой точности и надежности параметров связи, от числа факторов, корреляция с которыми изучается. Обычно считают, что число наблюдений должно быть не менее чем в 5-6, а лучше - не менее чем в 10 раз больше числа факторов. Еще лучше, если число наблюдений в несколько десятков или в сотни раз больше числа факторов, тогда закон больших чисел, действуя в полную силу, обеспечивает эффективное взаимопогашение случайных отклонений от закономерного характера связи признаков. Вторым условием закономерного проявления корреляционной связи служит условие, обеспечивающее надежное выражение закономерности в средней величине. Кроме уже указанного большого числа единиц совокупности для этого необходима достаточная качественная однородность совокупности. Нарушение этого условия можег извратить параметры корреляции. Например, в массе зерновых хозяйств уровень продукции с гектара растет по мере концентрации площадей, т.е. он выше в крупных хозяйствах. В массе овощных и овоще-молочных хозяйств (пригородный тип) наблюдается та же прямая связь уровня продукции с размером хозяйства. Но если соединить в общую неоднородную совокупность те и другие хозяйства, то связь уровня продукции с размером площади пашни (или посевной площади) получится обратной. Причина в том, что овощные и овоще-молочные хозяйства, имея меньшую площадь, чем зерновые, производят больше продукции с гектара ввиду большей интенсивности производства в данных отраслях, чем в производстве зерна. Иногда как условие корреляционного анализа выдвигают необходимость подчинения распределения совокупности по результативному и факторным признакам нормальному закону распределения вероятностей. Это условие связано с применением метода наименьших квадратов при расчете параметров корреляции: только при нормальном распределении метод наименьших квадратов дает оценку параметров, отвечающую принципам максимального правдоподобия. На практике эта. предпосылка чаще всего выполняется приближенно, но и тогда метод наименьших квадратов дает неплохие результаты. Однако при значительном отклонении распределений признаков от нормального закона нельзя оценивать надежность выборочного коэффициента корреляции, используя параметры нормального распределения вероятностей или распределения Стьюдента. Еще одним спорным вопросом является допустимость применения корреляционного анализа к функционально связанным признакам. Можно ли, например, построить уравнение корреляционной зависимости размеров выручки от продажи картофеля, от объема продажи и цены? Ведь произведение объема продажи и цены равно выручке в каждом отдельном случае. Как правило, к таким жестко детерминированным связям применяют только индексный метод анализа. Однако на этот вопрос можно взглянуть и с другой точки зрения. При индексном анализе выручки предполагается, что количество проданного картофеля и его цена независимы друг от друга, потому-то и допустима абстракция от изменения одного фактора при измерении влияния другого, как это принято в индексном методе (см. гл. 10). В реальности количество и цена не являются вполне независимыми друг от друга. Корреляционно-регрессионный анализ учитывает межфакторные связи, следовательно, дает нам более полное измерение роли каждого фактора: прямое, непосредственное его влияние на результативный признак; косвенное влияние фактора через его влияние на другие факторы; влияние всех факторов на результативный признак. Если связь между факторами несущественна, индексным анализом можно ограничиться. В противном случае его полезно дополнить корреляционно-регрессионным измерением влияния факторов, даже если они функционально связаны с результативным признаком. 8.3. Задачи корреляционно-регрессивного анализа и моделированияВ соответствии с сущностью корреляционной связи ее изучение имеет две цели: 1) измерение параметров уравнения, выражающего связь средних значений зависимой переменной со значениями независимой переменной (зависимость средних величин результативного признака от значений одного или нескольких факторных признаков); 2) измерение тесноты связи двух (или большего числа) признаков между собой. Вторая задача специфична для статистических связей, а первая разработана для функциональных связей и является общей. Основным методом решения задачи нахождения параметров уравнения связи является метод наименьших квадратов (МНК), разработанный К. Ф. Гауссом (1777-1855). Он состоит в минимизации суммы квадратов отклонений фактически измеренных значений зависимой переменной у от ее значений, вычисленных по уравнению связи с факторным признаком (многими признаками) х. Для измерения тесноты связи применяется несколько показателей. При парной связи теснота связи измеряется прежде всего корреляционным отношением, которое обозначается греческой буквой п. Квадрат корреляционного отношения - это отношение межгрупповой дисперсии результативного признака, которая выражает влияние различий группировочного факторного признака на среднюю величину результативного признака, к общей дисперсии результативного признака, выражающей влияние на него всех причин и условий. Квадрат корреляционного отношения называется коэффициентом детерминации: где k — число групп по факторному признаку; N - число единиц совокупности; yi - индивидуальные значения результативного признака; у̅j - его средние групповые значения; у̅ - его общее среднее значение; fj - частота в j-й группе. Формула (8.1) применяется при расчете показателя тесноты связи по аналитической группировке (см. гл. 6). При вычислении корреляционного отношения по уравнению связи (уравнению парной или множественной регрессии) применяется формула (8.2): где у̂i - индивидуальные значения у по уравнению связи. Сумма квадратов в числителе - это объясненная связью с фактором х (факторами) дисперсия результативного признака у. Она вычисляется по индивидуальным данным, полученным для каждой единицы совокупности на основе уравнения регрессии. Если уравнение выбрано неверно или сделана ошибка при расчете его параметров, то сумма квадратов в числителе может оказаться большей, чем в знаменателе, и отношение утратит тот смысл, который оно должно иметь, а именно какова доля общей вариации результативного признака, объясняемая на основе выбранного уравнения связи его с факторным признаком (признаками). Чтобы избежать ошибочного результата, лучше вычислять корреляционное отношение по другой формуле (8.3), не столь наглядно выявляющей сущность показателя, но зато полностью гарантирующей от возможного искажения:
В числителе формулы (8.3) стоит сумма квадратов отклонений фактических значений признака у от его индивидуальных расчетных значений, т. е. доля вариации этого признака, не объясняемая за счет входящих в уравнение связи признаков-факторов. Эта сумма не может стать равной нулю, если связь не является функциональной. При неверной формуле уравнения связи или ошибке в расчетах возрастают расхождения фактических и расчетных значений, и корреляционное отношение снижается, как логически и должно быть. В основе перехода от формулы (8.2) к формуле (8.3) лежит известное правило разложения сумм квадратов отклонений при группировке совокупности:
Согласно этому правилу можно вместо межгрупповой (факторной) дисперсии использовать разность:
При расчете h не по группировке, а по уравнению корреляционной связи (уравнению регрессии) мы используем формулу (8.3). В этом случае правило разложения суммы квадратов отклонений результативного признака записывается как
Важнейшее положение, которое следует теперь усвоить любому, желающему правильно применять метод корреляционно-регрессионного анализа, состоит в интерпретации формул (8.2) и (8.3). Это положение гласит: Уравнение корреляционной связи измеряет зависимость между вариацией результативного признака и вариацией факторного признака (признаков). Меры тесноты связи измеряют долю вариации результативного признака, которая связана корреляционно с вариацией факторного признака (признаков). Интерпретировать корреляционные показатели строго следует лишь в терминах вариации (различий в пространстве) отклонений от средней величины. Если же задача исследования состоит в измерении связи не между вариацией двух признаков в совокупности, а между изменениями признаков объекта во времени, то метод корреляционно-регрессионного анализа требует значительного изменения (см. гл. 9). Из вышеприведенного положения об интерпретации показателей корреляции следует, что нельзя трактовать корреляцию признаков как связь их уровней. Это ясно хотя бы из следующего примера. Если бы все крестьяне области внесли под картофель одинаковую дозу удобрений, то вариация этой дозы была бы равна нулю, а следовательно, она абсолютно не могла бы влиять на вариацию урожайности картофеля. Параметры корреляции дозы удобрений с урожайностью будут тогда строго равны нулю. Но ведь и в этом случае уровень урожайности зависел бы от дозы удобрений - он был бы выше, чем без удобрений. Итак, строго говоря, метод корреляционно-регрессионного анализа не может объяснить роли факторных признаков в создании результативного признака. Это очень серьезное ограничение метода, о котором не следует забывать. Следующий общий вопрос - это уже рассмотренный в разделе о группировке вопрос о «чистоте» измерения влияния каждого отдельного факторного признака. Как отмечалось в главе 6, группировка совокупности по одному факторному признаку может отразить влияние именно данного фактора на результативный признак при условии, что все другие факторы не связаны с изучаемым, а случайные отклонения и ошибки взаимопогасились в большой совокупности. Если же изучаемый фактор связан с другими факторами, влияющими на результативный признак, будет получена не «чистая» характеристика влияния только одного фактора, а сложный комплекс, состоящий как из непосредственного влияния фактора, так и из его косвенных влияний, через его связь с другими факторами и их влияние на результативный признак. Данное положение полностью относится и к парной корреляционной связи. Однако коренное отличие метода корреляционно-регрессионного анализа от аналитической группировки состоит в том, что корреляционно-регрессионный анализ позволяет разделить влияние комплекса факторных признаков, анализировать различные стороны сложной системы взаимосвязей. Если метод комбинированной аналитической группировки, как правило, не дает возможность анализировать более 3 факторов, то корреляционный метод при объеме совокупности около ста единиц позволяет вести анализ системы с 8-10 факторами и разделить их влияние. Наконец, развивающиеся на базе корреляционно-регрессионного анализа многомерные методы (метод главных компонент, факторный анализ) позволяют синтезировать влияние признаков (первичных факторов), выделяя из них непосредственно не учитываемые глубинные факторы (компоненты). Например, изучая корреляцию ряда признаков интенсификации сельскохозяйственного производства, таких, как фондообеспеченность, затраты труда на единицу площади, энергообеспеченность, внесение удобрений на единицу площади, плотность поголовья скота, можно синтезировать общую часть их влияния на уровень продукции с единицы площади или на производительность труда, получив обобщенный фактор «интенсификация производства», непосредственно не измеримый, не отражаемый единым показателем. Правильное применение и интерпретация результатов корреляционно-регрессионного анализа возможны лишь при понимании всех специфических черт, достоинств и ограничений метода. Поэтому нужно рекомендовать вернуться к данному разделу заново после изучения остальных разделов данной главы и после приобретения некоторой практики применения метода к решению различных задач. Необходимо сказать и о других задачах применения корреляционно-регрессионного метода, имеющих не формально математический, а содержательный характер. 1. Задача выделения важнейших факторов, влияющих на результативный признак (т.е. на вариацию его значений в совокупности). Эта задача решается в основном на базе мер тесноты связи факторов с результативным признаком. 2. Задача оценки хозяйственной деятельности по эффективности использования имеющихся факторов производства. Эта задача решается путем расчета для каждой единицы совокупности тех величин результативного признака, которые были бы получены при средней по совокупности эффективности использования факторов и сравнения их с фактическими результатами производства, 3. Задача прогнозирования возможных значений результативного признака при задаваемых значениях факторных признаков. Такая задача решается путем подстановки ожидаемых, или планируемых, или возможных значений факторных признаков в уравнение связи и вычисления ожидаемых значений результативного признака. Приходится решать и обратную задачу: вычисление необходимых значений факторных признаков для обеспечения планового или желаемого значения результативного признака в среднем по совокупности. Эта задача обычно не имеет единственного решения в рамках данного метода и должна дополняться постановкой и решением оптимизационной задачи на нахождение наилучшего из возможных вариантов ее решения (например, варианта, позволяющего достичь требуемого результата с минимальными затратами). 4. Задача подготовки данных, необходимых в качестве исходных для решения оптимизационных задач. Например, для нахождения оптимальной структуры производства в районе на перспективу исходная информация должна включать показатели производительности на предприятиях разных отраслей и форм собственности. В свою очередь, эти показатели могут быть получены на основе корреляционно-регрессионной модели либо на основании тренда динамического ряда (а тренд - это тоже уравнение регрессии). При решении каждой из названных задач нужно учитывать особенности и ограничения корреляционно-регрессионного метода. Всякий раз необходимо специально обосновать возможность причинной интерпретации уравнения как объясняющего связь между вариацией фактора и результата. Трудно обеспечить раздельную оценку влияния каждого из факторов. В этом отношении корреляционные методы глубоко противоречивы. С одной стороны, их идеал - измерение чистого влияния каждого фактора. С другой стороны, такое измерение возможно при отсутствии связи между факторами и случайной вариации признаков. А тогда связь является функциональной, и корреляционные методы анализа излишни. В реальных системах связь всегда имеет статистический характер, и тогда идеал методов корреляции становится недостижимым. Но это не значит, что эти методы не нужны. Данное противоречие означает попросту недостижимость абсолютной истины в познании реальных связей. Приближенный характер любых результатов корреляционно-регрессионного анализа не является поводом для отрицания их полезности. Всякая научная истина - относительна. Забыть об этом и абсолютизировать параметры регрессионных уравнений, меры корреляции было бы ошибкой, так же как и отказаться от использования этих мер. 8.4. Вычисление и интерпретация параметров парной линейной корреляцииПростейшей системой корреляционной связи является линейная связь между двумя признаками - парная линейная корреляция. Практическое значение ее в том, что есть системы, в которых среди всех факторов, влияющих на результативный признак, выделяется один важнейший фактор, который в основном определяет вариацию результативного признака. Измерение парных корреляций составляет необходимый этап в изучении сложных, многофакторных связей. Есть такие системы связей, при изучении которых следует предпочесть парную корреляцию. Внимание к линейным связям объясняется ограниченной вариацией переменных и тем, что в большинстве случаев нелинейные формы связей для выполнения расчетов преобразуются в линейную форму. Уравнение парной линейной корреляционной связи называется уравнением парной регрессии и имеет вид: у = а + bх, (8.4) где у - среднее значение результативного признака> при определенном значении факторного признака х; а - свободный член уравнения; b - коэффициент регрессии, измеряющий среднее отношение отклонения результативного признака от его средней величины к отклонению факторного признака от его средней величины на одну единицу его измерения - вариация у, приходящаяся на единицу вариации х. Что касается термина регрессия, его происхождение таково: создатели корреляционного анализа Ф. Гальтон (1822 - 1911) и К. Пирсон (1857 - 1936) интересовались связью между ростом отцов и их сыновей. Ф. Гальтон изучил более 200 семей и обнаружил, что в группе семей с высокорослыми отцами сыновья в среднем ниже ростом, чем их отцы, а в группе семей с низкорослыми отцами сыновья в среднем выше отцов. Таким образом, отклонение роста от средней в следующем поколении уменьшается -регрессирует. Причина в том, что на рост сыновей влияет не только рост отцов, но и рост матерей и много других факторов развития ребенка, и эти факторы, случайно направленные как в сторону увеличения, так и снижения роста, приближают рост сыновей к среднему росту. В целом же вариация роста, конечно, не уменьшается, а в наше время «акселерации» сам средний рост увеличивается из поколения в поколение. Уравнение (8.4) определяется по данным о значениях признаков х и у в изучаемой совокупности, состоящей из п единиц. Параметры уравнения а и b находятся методом наименьших квадратов (МНК). Исходное условие МНК для прямой линии имеет вид:
Для отыскания значений параметров а ч b, при которых f(a,b) принимает минимальное значение, частные производные функции приравниваем нулю и преобразуем получаемые уравнения, которые называются нормальными уравнениями МНК для прямой:
Отсюда система нормальных уравнений имеет вид:
Нормальные уравнения МНК для прямой линии регрессии являются системой двух уравнений с двумя неизвестными а и b. Все остальные величины, входящие в систему, определяются по исходной информации. Таким образом, однозначно вычисляются при решении этой системы уравнений оба параметра уравнения линейной регрессии. Если первое нормальное уравнение разделить на п, получим:
По уравнению (8.6) обычно на практике вычисляется свободный член уравнения регрессии а. Параметр b вычисляется по преобразованной формуле, которую можно вывести, решая систему нормальных уравнений относительно b:
Так как знаменатель этого выражения есть не что иное, как дисперсия признака х, т. е. ст2^, то можно записать формулу коэффициента регрессии в виде:
Подставив в (8.8) выражение для s2x, получим:
Параметры уравнения регрессии можно вычислить через определители:
где D - определитель системы; Da - частный определитель, получаемый в результате замены коэффициентов при а свободными членами из правой части системы уравнений; Db - частный определитель, получаемый в результате замены коэффициентов при b свободными членами из правой части системы уравнений. Формулы (8.10) соответствуют самому общему подходу к определению параметров уравнения регрессии и могут применяться в случае как парной, так и множественной регрессии. Применение одной из формул (8.7), (8.8) или (8.9) зависит от характера данных и наличия уже вычисленных на предыдущих этапах анализа показателей. Если были вычислены x̅, y̅, sx, sy, то проще применить формулу (8.7) или (8.8). Если расчет параметров уравнения корреляционной связи ведется исходя из первичных данных хi, уi, то удобнее формула (8.9). Особенно существенно она сокращает объем вычислений при слабой вариации признаков, ибо тогда отклонения их индивидуальных значений от средних величин на порядок или два меньше самих индивидуальных и средних величин. Кроме того, формула (8.9) явно выражает указанную в п. 8.1 особенность корреляционного анализа связей: параметры корреляции зависят не от уровней признаков, а только от их отклонений от средних значений. Если значение признака увеличить в 10 раз, корреляция не изменится, также не изменятся параметры корреляции, кроме свободного члена, если ко всем значениям каждого признака прибавить постоянное число. Коэффициент парной линейной регрессии, обозначенный Ь, имеет смысл показателя силы связи между вариацией факторного признака х и вариацией результативного признака у. Он измеряет среднее по совокупности отклонение у от его средней величины при отклонении признака х от своей средней величины на принятую единицу измерения. Например, по данным табл. 8.1 при отклонении затрат на 1 корову от средней величины на 1 руб. надой молока на корову отклоняется от своего среднего значения на 3,47 кг в среднем по совокупности. При отклонении фактора на х̅i - х̅ результативный признак отклоняется в среднем на у̅i - у̅. Теснота парной линейной корреляционной связи, как и любой другой показатель, может быть измерена корреляционным отношением h. Кроме того, при линейной форме уравнения применяется другой показатель тесноты связи - коэффициент корреляции rxy. Этот показатель представляет собой стандартизованный коэффициент регрессии, т. е. коэффициент, выраженный не в абсолютных единицах измерения признаков, а в долях среднего квадратического отклонения результативного признака:
Коэффициент корреляции был предложен английским статистиком и философом Карлом Пирсоном (1857 - 1936). Его интерпретация такова: отклонение признака-фактора от его среднего значения на величину своего среднего квадратического отклонения в среднем по совокупности приводит к отклонению признака-результата от своего среднего значения на rxy его среднего квадратического отклонения. В отличие от коэффициента регрессии b коэффициент корреляции не зависит от принятых единиц измерения признаков, а стало быть, он сравним для любых признаков. Обычно считают связь сильной, если r ³. 0,7; средней тесноты, при 0,5 £ r £ 0,7; слабой при г < 0,5. Не следует, особенно работая с ЭВМ, гнаться за большим числом знаков коэффициента корреляции. Во-первых, исходная информация редко имеет более трех значащих точных цифр, во-вторых, оценка тесноты связи не требует более двух значащих цифр. Квадрат коэффициента корреляции называется коэффициентом детерминации:
Эта формула понадобится при. анализе множественной корреляции. Умножив числитель и знаменатель (8.12) на
Это выражение соответствует выражению г\2 (см. формулу (8.2)). Тождество коэффициента детерминации и квадрата корреляционного отношения служит основанием для интерпретации величины г2 как доли общей дисперсии результативного признака у, которая объясняется вариацией признака-фактора х (и связью между вариацией обоих признаков). Собственно говоря, основным показателем тесноты связи и следовало бы считать коэффициент детерминации (для линейной формулы связи) или квадрат корреляционного отношения. Но исторически раньше был введен коэффициент корреляции, который долгое время и рассматривался как основной показатель. Аналогично разным «рабочим» формулам для вычисления коэффициента регрессии можно на основе исходной формулы (8.10) подучить разные «рабочие» формулы коэффициента корреляции. 1. Разделив числитель и знаменатель формулы (8.11) на п, получим: 2.
Эта формула соответствует формуле (8.8) для коэффициента регрессии. 2. Средние квадратические отклонения можно выразить через средние величины признака: Подставив эти выражения в (8.14), получим: Эта формула (8.15) удобнее для расчетов, если средние величины признаков и средние квадраты индивидуальных величин вычислены ранее. Смысл же коэффициента корреляции раскрывается исходной формулой (8.11). В преобразованных формулах этот смысл не столь ясен. Рассмотрим фактический пример анализа корреляционной парной линии связи по данным 16 сельхозпредприятий о затратах на 1 корову и о надое молока на корову. Ограниченный объем совокупности принят только в учебных целях, чтобы избежать приведения громоздких таблиц (табл. 8.1). Средние значения признаков: x̅ = 1605 руб.; у̅ = 35,2 ц/голов. Сопоставляя знаки отклонений признаков jc и у от средних величин, видим явное преобладание совпадающих по знакам пар отклонений: их 14 и только 2 пары несовпадающих знаков. Таблица 8.1 Корреляция между затратами на корову и надоем молока в среднем от коровы
Немецкий психиатр Г. Т. Фехнер (1801 - 1887) предложил меру тесноты связи в виде отношения разности числа пар совпадающих и несовпадающих пар знаков к сумме этих чисел:
Конечно, коэффициент Фехнера - очень грубый показатель тесноты связи, не учитывающий величину отклонений признаков от средних значений, но он может служить некоторым ориентиром в оценке интенсивности связи. В данном случае он указывает на тесную связь признаков. Вычислим на основе итоговой строки табл. 8.1 параметр парной линейной корреляции:
Он означает, что в среднем по изучаемой совокупности отклонение затрат на 1 корову от средней величины на 1 руб. приводило к отклонению с тем же знаком среднего надоя молока на 0,0347 ц, т. е. на 3,47 кг на корову. При нестрогой интерпретации говорят: «С увеличением затрат на корову на 1 руб. в среднем надой молока возрастал на 3,47 кг». Поскольку и до начала резкой инфляции стоимость 3,47 кг молока значительно превосходила рубль, увеличение затрат на корову было экономически целесообразным. Свободный член уравнения регрессии вычислим по формуле (8.6): а = 35,2 - 0,0347 • 1605 = - 20,49. Уравнение регрессии в целом имеет вид:
Отрицательная величина свободного члена уравнения означает, что область существования признака у не включает нулевого значения признакам и близких значений. Можно рассчитать минимально возможную величину фактора х, при которой обеспечивается наименьшее значение признака у (разумеется, положительное).
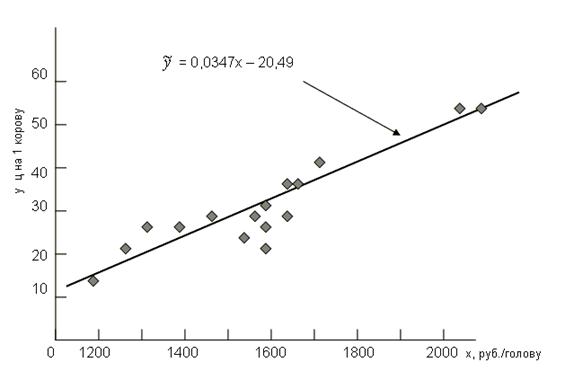
- это наименьшая сумма затрат на 1 корову, при которых корова способна давать молоко. Если же область существования результативного признака^включает нулевое значение признака-фактора, то свободный член является положительным и означает среднее значение результативного признака при отсутствии данного фактора, например среднюю урожайность картофеля при отсутствии органических удобрений. Графическое изображение корреляционной связи по данным табл. 8.1. приведено на рис. 8.1. Коэффициент корреляции, рассчитанный на основе табл. 8.1,
Рис. 8.1. Корреляция затрат на корову с продуктивностью
8.5. Статистическая оценка надежности параметров парной корреляцииПоказатели корреляционной связи, вычисленные по ограниченной совокупности (по выборке), являются лишь оценками той или иной статистической закономерности, поскольку в любом параметре сохраняется элемент не полностью погасившейся случайности, присущей индивидуальным значениям признаков. Поэтому необходима статистическая оценка степени точности и Надежности параметров корреляции. Под надежностью здесь понимается вероятность того, что значение проверяемого параметра не равно нулю, не включает в себя величины противоположных знаков. Вероятностная оценка параметров корреляции производится по общим правилам проверки статистических гипотез, разработанным математической статистикой, в частности путем сравнения оцениваемой величины со средней случайной ошибкой оценки. Для коэффициента парной регрессии Ъ средняя ошибка оценки вычисляется как:
Числитель подкоренного выражения есть остаточная дисперсия результативного признака. В примере по данным табл. 8.1 средняя ошибка оценки коэффициента регрессии
Зная среднюю ошибку оценки коэффициента регрессии, можно-вычислить вероятность того, что нулевое значение коэффициента входит в интервал возможных с учетом ошибки значений. С этой целью находится отношение коэффициента к его средней ошибке, т. е. t-критерий Стьюдента:
Табличное значение t-критерия Стьюдента при 16-2 степенях свободы и уровне значимости 0,01 составляет 2,98 (см. приложение, табл. 2). Полученное значение критерия много больше, следовательно, вероятность нулевого значения коэффициента регрессии менее 0,01. Гипотезу о несущественности этого коэффициента можно отклонить: данные табл. 8.1 надежно говорят о влиянии вариации затрат на корову на вариацию надоя молока от коров. Расчет критерия Стьюдента для коэффициентов регрессии входит в программы ЭВМ и ПЭВМ для корреляционного анализа, например «Mikrostat», MAKR-4, «Statgraphics» и др. Надежность установления связи можно проверить и по средней случайной ошибке коэффициента корреляции, вычисляемой по формуле:
Проверим значимость заведомо бессодержательного коэффициента корреляции надоя от коров с числом букв в названии сельхоз-предприятия:
Полученное значение t намного ниже его критического значения даже для значимости 0,1, составляющего 1,76. Следовательно, вероятность того, что нулевое значение коэффициента входит в возможный интервал его оценок значительно больше 0,1 и нулевая гипотеза не может быть отброшена. Конечно, анекдотический характер фактора «число букв» позволяет сделать решительный вывод об отсутствии связи. Если же проверяемый фактор на самом деле мог влиять на результативный признак, то вывод следует формулировать не в терминах отсутствия связи, а в том, что по изучаемой информации связь надежно не установлена. Если коэффициент корреляции близок к единице, то распределение его оценок отличается от нормального или распределения Стьюдента, так как он ограничен величиной 1. В таких случаях Р. Фишер предложил для оценки надежности коэффициента преобразовывать его величину в форму, не имеющую такого ограничения:
Средняя ошибка величины z определяется по формуле
Величину z можно взять из табл. 6 приложения. Проверим этим способом надежность коэффициента корреляции надоя молока с затратами на 1 корову:
Значение критерия Стьюдента намного больше его критического значения для значимости 0,01. Следовательно, коэффициент корреляции с очень большой вероятностью больше нуля; связь установлена надежно. Для оценки надежности коэффициента корреляции можно воспользоваться таблицей критических значений для заданных уровней значимости (0,05 или 0,01) и числа степеней свободы (см. приложение, табл. 5). Например, по выборке объемом 32 единицы получен парный коэффициент корреляции 0,319. Число степеней свободы для него равно 30, поскольку в расчете г участвуют две величины, значения которых закреплены - х̅ и у̅. За счет этого мы теряем две степени свободы: 32 - 2. Так как критическое значение для 30 степеней свободы равно (при уровне значимости 0,05) 0,3494, то полученное значение ниже критического по модулю. Соответственно, гипотеза о связи признаков надежно не доказана. Неверен вывод и об отсутствии связи -он также надежно не доказан. Из табл. 5 приложения видно, что при малой выборке надежно можно установить только тесные связи, а при большой численности совокупности, например, 102 единицы, надежно измеряются и слабые связи. Этот вывод важен для практической работы по корреляционному анализу. Можно рассчитать доверительный интервал оценки коэффициента корреляции с заданной вероятностью, скажем, 0,95. При этих условиях и 13 степенях свободы вариации значение t-критерия Стьюдента равно 2,16. Тогда доверительный интервал для z составит: 1,564 ± 2,16·0,2774, т. е. от 0,965 до 2,163. Подставив эти граничные значения z в формулу (8.18), получаем границы интервала значений коэффициента корреляции: от 0,974 до 0,747. Как видим, с большой вероятностью связь на самом деле является весьма тесной, коэффициент корреляции не ниже 0,7. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
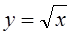 , но значению х = 4 соответствует не одно, а два значения: у1 = +2; у2 = - 2. Уравнения более высоких степеней могут иметь несколько корней, связь, разумеется, остается функциональной.
, но значению х = 4 соответствует не одно, а два значения: у1 = +2; у2 = - 2. Уравнения более высоких степеней могут иметь несколько корней, связь, разумеется, остается функциональной.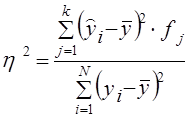 , (8.1)
, (8.1)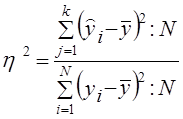 , (8.2)
, (8.2)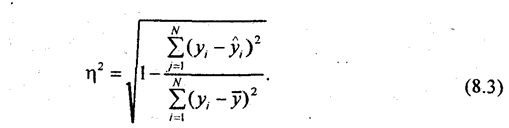
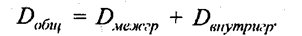
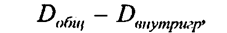

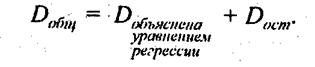
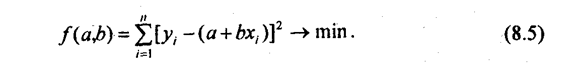
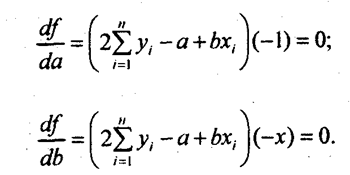
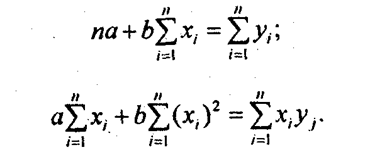
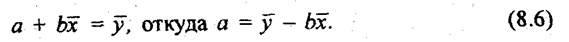
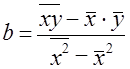 . (8.7)
. (8.7)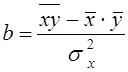 (8-8)
(8-8)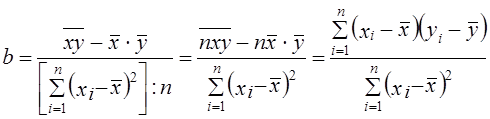 . (8.9)
. (8.9)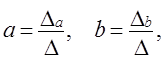 (8.10)
(8.10)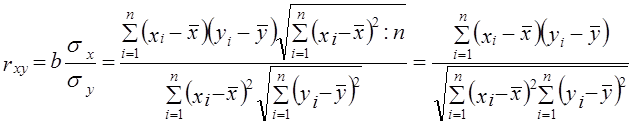 . (8.11)
. (8.11)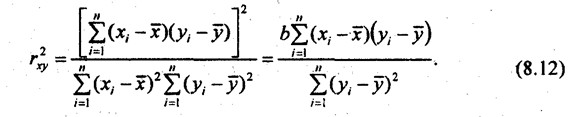
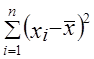 получим:
получим: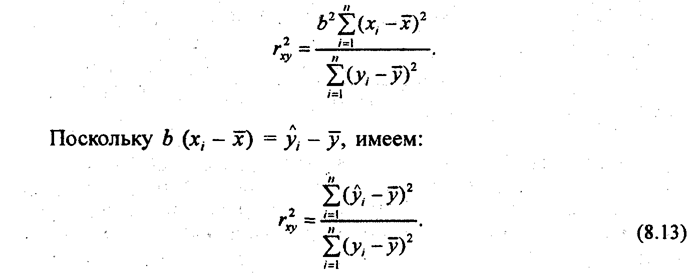
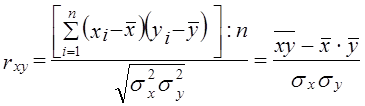 . (8.14)
. (8.14)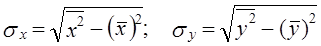 .
. 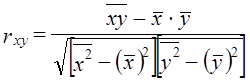 . (8.15)
. (8.15)